集群三部曲(三):完美的Spark集群搭建
前面已经成功的搭建了Zookeeper和Hadoop集群,接下来让我们更进一步,实现Spark集群的搭建吧。相比较而言,Spark集群的搭建要简单的许多了,关键是Hadoop已经搭建成功了。此次是基于上次的Hadoop,因为Spark是依赖于Hadoop提供的分布式文件系统的。好了,让我们扬帆起航吧!
一、环境:虚拟机CentOs7系统,完整的环境,请确认已安装JDK、Hadoop及Spark安装包,节点仍然使用上次克隆的两个,下面先进行其中一个的环境搭建。
二、Spark配置(解压啥的不说了)
配置前说下几个关键词:Master、Worker,了解一下。
(1)配置环境变量
vim /etc/profile修改如下:
JAVA_HOME=/usr/java/jdk1.8.0_161
JRE_HOME=/usr/java/jdk1.8.0_161/jre
SCALA_HOME=/usr/local/scala
HADOOP_HOME=/usr/local/hadoop
SPARK_HOME=/usr/local/spark
ZOOKEEPER_HOME=/usr/local/zookeeper
KAFKA_HOME=/usr/local/kafka
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export JAVA_HOME JRE_HOME SCALA_HOME HADOOP_HOME SPARK_HOME ZOOKEEPER_HOME KAFKA_HOME PATH CLASSPATH
修改完成后,记得运行命令source使之生效,将其拷贝到另外两个服务器上并进行相同操作,切记。
(2)配置conf目录下的文件
首先配置spark-env.sh文件,复制一份并改名:
cp spark-env.sh.template spark-env.sh编辑文件,添加配置(根据自己需要):
#!/usr/bin/env bash
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export JAVA_HOME=/usr/java/jdk1.8.0_161
export SCALA_HOME=/usr/local/scala
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export SPARK_HOME=/usr/local/spark
然后配置slaves文件,复制一份并改名:
cp slaves.template slaves编辑文件,并配置(只加入datanode节点的服务器名):
slave02
slave03(3)启动和测试Spark集群
因为Spark是依赖于Hadoop提供的分布式文件系统的,所以在启动Spark之前,先确保Hadoop在正常运行。之前已经成功搭建了Hadoop集群,所以这里直接启动即可:
#hadoop的/sbin目录下
./start-all.sh启动后,执行jps查看是否正常启动
(此处可参考:https://my.oschina.net/u/3747963/blog/1636026)
接下来启动Spark:
#Spark /sbin目录下
./start-all.sh启动后,执行jps查看是否正常启动,如下:
[hadoop@slave01 sbin]$ jps
42657 Master
42004 SecondaryNameNode
42741 Jps
42182 ResourceManager
41768 NameNode
在slave02和slave03上执行jps,如下:
[hadoop@slave02 conf]$ jps
15685 Worker
15238 DataNode
15756 Jps
15388 NodeManager
从上面可以看出,已经成功启动了Spark,在浏览器里访问Master机器,即slave01,访问http://slave01:8080:
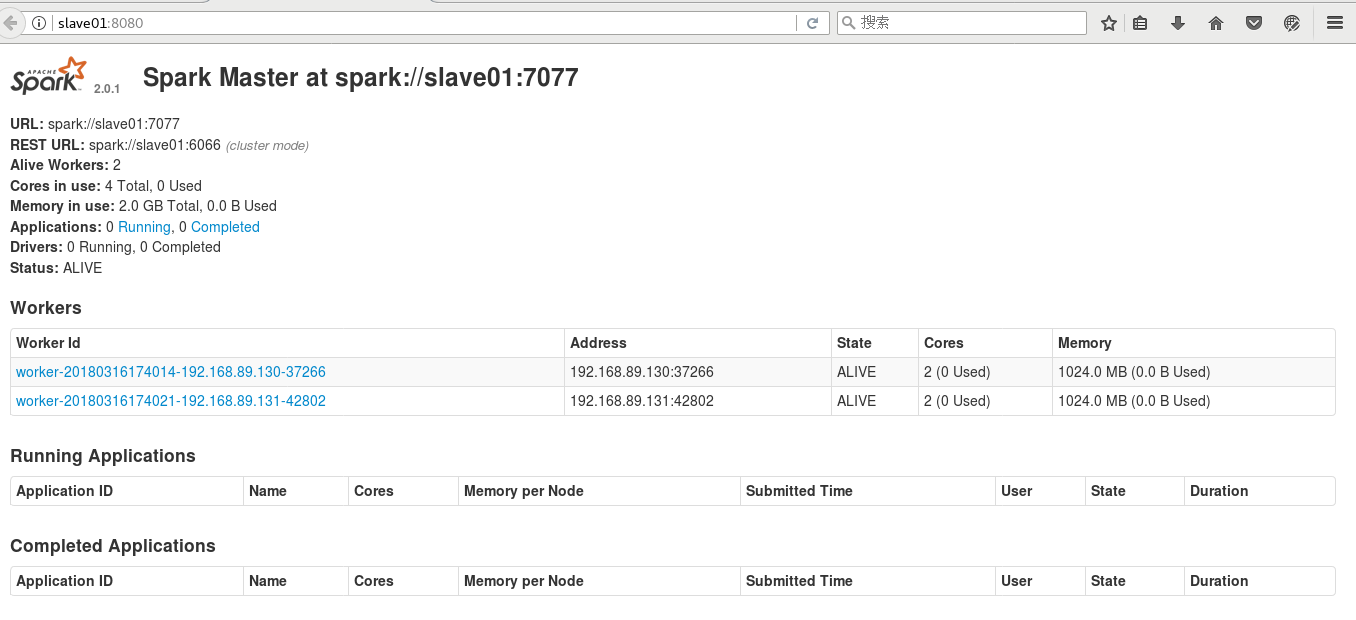
好了,关于大数据的三个集群的搭建已经全部完成了,如果大家有什么疑问,欢迎一起讨论。
文章来源:
Author:海岸线的曙光
link:https://my.oschina.net/u/3747963/blog/1636092