集群三部曲(二):完美的Hadoop集群搭建
继上次Zookeeper集群的搭建成功后,现在来说下Hadoop的集群搭建。好了,闲话不多说,让我们开始今天的冒险之旅吧。
一、环境:虚拟机CentOs7系统,完整的环境,请确认已安装JDK,及Hadoop安装包(本人用的是2.9.0),节点仍然使用上次克隆的两个,下面先进行其中一个的环境搭建。
二、Hadoop配置(自己解压哈)
配置前说明一下(很重要,拿本子记一下):首先,namenode,datanode,ResourceManager了解一下,这里准备将slave01作为namenode,slave02和slave03作为datanode,下面的操作都是以这个为前提展开的,请大家做好战前温习,以防不知下面的操作的意义。开始表演吧:
解压后文件目录结构基本如下:
[hadoop@slave01 hadoop]$ pwd
/usr/local/hadoop
[hadoop@slave01 hadoop]$ ls
bin include libexec logs README.txt share
etc lib LICENSE.txt NOTICE.txt sbin tmp
[hadoop@slave01 hadoop]$ cd etc/hadoop/
[hadoop@slave01 hadoop]$ ls
capacity-scheduler.xml httpfs-env.sh mapred-env.sh
configuration.xsl httpfs-log4j.properties mapred-queues.xml.template
container-executor.cfg httpfs-signature.secret mapred-site.xml.template
core-site.xml httpfs-site.xml slaves
hadoop-env.cmd kms-acls.xml ssl-client.xml.example
hadoop-env.sh kms-env.sh ssl-server.xml.example
hadoop-metrics2.properties kms-log4j.properties yarn-env.cmd
hadoop-metrics.properties kms-site.xml yarn-env.sh
hadoop-policy.xml log4j.properties yarn-site.xml
hdfs-site.xml mapred-env.cmd
关闭防火墙,大家了解一下:
systemctl stop firewalld #只在本次运用时生效,下次开启机器时需重复此操作
或
systemctl disable firewalld #此命令在下次重启时生效,将永久关闭防火墙(1)将Hadoop添加到环境变量中
vim /etc/profile添加HADOOP_HOME,修改如下:
JAVA_HOME=/usr/java/jdk1.8.0_161
JRE_HOME=/usr/java/jdk1.8.0_161/jre
SCALA_HOME=/usr/local/scala
HADOOP_HOME=/usr/local/hadoop
ZOOKEEPER_HOME=/usr/local/zookeeper
KAFKA_HOME=/usr/local/kafka
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$SCALA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$KAFKA_HOME/bin
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export JAVA_HOME JRE_HOME SCALA_HOME HADOOP_HOME ZOOKEEPER_HOME KAFKA_HOME PATH CLASSPATH
查看Hadoop解压目录下:/etc/hadoop/hadoop-env.sh文件中配置是否正常:
# The java implementation to use.
export JAVA_HOME=/usr/java/jdk1.8.0_161
# The jsvc implementation to use. Jsvc is required to run secure datanodes
# that bind to privileged ports to provide authentication of data transfer
# protocol. Jsvc is not required if SASL is configured for authentication of
# data transfer protocol using non-privileged ports.
#export JSVC_HOME=${JSVC_HOME}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/etc/hadoop"}
JAVA_HOME改为自己本机jdk安装地址。
(2)修改core-site.xml文件
从上面的目录结构中找到该文件,打开后显示的初始配置如下:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
进行如下修改:
<configuration>
<!-- 指定Hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<!-- 指定HDFS的namenode的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://slave01:9000</value>
</property>
</configuration>
(3)修改hdfs-site.xml文件
从上面的目录结构中找到该文件,打开后显示的初始配置如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
进行如下修改:
<configuration>
<!-- 设置namenode的http通信地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>slave01:50070</value>
</property>
<!-- 设置hdfs副本数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 设置namenode存放路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<!--设置datanode存放路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
此处可添加其他的配置参数,在此不做介绍,可自行百度查看,注意设置的存放路径的文件夹的创建,若不存在,则创建。
(4)修改mapred-site.xml文件
首先复制一份该文件的temple,重新命名:
cp mapred-site.xml.template mapred-site.xml初始内容为空,修改后如下:
<configuration>
<!-- 指定mapreduce框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>(5)修改yarn-site.xml文件
初始内容为空,修改后如下:
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 设置 resourcemanager 在哪个节点-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave01</value>
</property>
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
(6)修改slaves文件(只需将作为datanode的服务器名加上即可)
slave02
slave03(7)拷贝配置文件到其他服务器
若不想一个一个的进行文件配置,可以将已经配置好的文件拷贝到其他需要的服务器上,注意拷贝成功后执行命令:source /etc/profile使之生效:
//slave01上的/etc/profile文件拷贝到slave02
scp -r /etc/profile slave02:/etc/profile
//slave01上的/usr/local/hadoop文件夹整个目录拷贝到slave02
scp -r /usr/local/hadoop slave02:/usr/local/(8)格式化HDFS
在namenode节点的服务器即slave01上执行命令:
hdfs namenode -format
格式化成功则显示如下:
8/03/16 15:40:23 INFO namenode.FSDirectory: XAttrs enabled? true
18/03/16 15:40:23 INFO namenode.NameNode: Caching file names occurring more than 10 times
18/03/16 15:40:23 INFO snapshot.SnapshotManager: Loaded config captureOpenFiles: falseskipCaptureAccessTimeOnlyChange: false
18/03/16 15:40:23 INFO util.GSet: Computing capacity for map cachedBlocks
18/03/16 15:40:23 INFO util.GSet: VM type = 64-bit
18/03/16 15:40:23 INFO util.GSet: 0.25% max memory 889 MB = 2.2 MB
18/03/16 15:40:23 INFO util.GSet: capacity = 2^18 = 262144 entries
18/03/16 15:40:23 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
18/03/16 15:40:23 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
18/03/16 15:40:23 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
18/03/16 15:40:23 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
18/03/16 15:40:23 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
18/03/16 15:40:23 INFO util.GSet: Computing capacity for map NameNodeRetryCache
18/03/16 15:40:23 INFO util.GSet: VM type = 64-bit
18/03/16 15:40:23 INFO util.GSet: 0.029999999329447746% max memory 889 MB = 273.1 KB
18/03/16 15:40:23 INFO util.GSet: capacity = 2^15 = 32768 entries
Re-format filesystem in Storage Directory /usr/local/hadoop/tmp/dfs/name ? (Y or N) y
18/03/16 15:40:26 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1094714660-127.0.0.1-1521186026480
18/03/16 15:40:26 INFO common.Storage: Will remove files: [/usr/local/hadoop/tmp/dfs/name/current/VERSION, /usr/local/hadoop/tmp/dfs/name/current/seen_txid, /usr/local/hadoop/tmp/dfs/name/current/fsimage_0000000000000000000.md5, /usr/local/hadoop/tmp/dfs/name/current/fsimage_0000000000000000000, /usr/local/hadoop/tmp/dfs/name/current/edits_0000000000000000001-0000000000000000004, /usr/local/hadoop/tmp/dfs/name/current/fsimage_0000000000000000004.md5, /usr/local/hadoop/tmp/dfs/name/current/fsimage_0000000000000000004, /usr/local/hadoop/tmp/dfs/name/current/edits_0000000000000000005-0000000000000000005, /usr/local/hadoop/tmp/dfs/name/current/edits_inprogress_0000000000000000006]
18/03/16 15:40:26 INFO common.Storage: Storage directory /usr/local/hadoop/tmp/dfs/name has been successfully formatted.
18/03/16 15:40:26 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
18/03/16 15:40:26 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/tmp/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 323 bytes saved in 0 seconds.
18/03/16 15:40:26 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
18/03/16 15:40:26 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at slave01/127.0.0.1
************************************************************/
[hadoop@slave01 hadoop]$ 中间有要操作的直接按提示即可,注意,下面说下报错的情况,可能很多同学在配置的时候都可能遇到过,折腾不少时间吧:
18/03/16 15:54:14 WARN namenode.NameNode: Encountered exception during format:
java.io.IOException: Cannot remove current directory: /usr/local/hadoop/tmp/dfs/name/current
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.clearDirectory(Storage.java:358)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:571)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:592)
at org.apache.hadoop.hdfs.server.namenode.FSImage.format(FSImage.java:166)
at org.apache.hadoop.hdfs.server.namenode.NameNode.format(NameNode.java:1172)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1614)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1741)
18/03/16 15:54:14 ERROR namenode.NameNode: Failed to start namenode.
java.io.IOException: Cannot remove current directory: /usr/local/hadoop/tmp/dfs/name/current
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.clearDirectory(Storage.java:358)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:571)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:592)
at org.apache.hadoop.hdfs.server.namenode.FSImage.format(FSImage.java:166)
at org.apache.hadoop.hdfs.server.namenode.NameNode.format(NameNode.java:1172)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1614)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1741)
18/03/16 15:54:14 INFO util.ExitUtil: Exiting with status 1: java.io.IOException: Cannot remove current directory: /usr/local/hadoop/tmp/dfs/name/current
18/03/16 15:54:14 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at slave02/127.0.0.1
************************************************************/
[hadoop@slave02 hadoop]$ 报错的原因呢,只是因为没有设置 /usr/local/hadoop/tmp文件夹的权限,悲伤辣么大,我竟无言以对。解决方法,当然是给这个目录加上权限了,chmod了解一下,在三个服务器上都进行该操作:
sudo chmod -R a+w /usr/local/hadoop到此呢,基本的配置已经完成了。当然,还有许多的配置没有使用,这里只是做个初步简单的集群。
(三)启动hadoop集群
(1)在slave01上执行如下命令
start-dfs.sh
start-yarn.sh
jps启动成功显示如下:
[hadoop@slave01 sbin]$ ./start-dfs.sh
Starting namenodes on [slave01]
slave01: namenode running as process 26894. Stop it first.
The authenticity of host 'slave03 (192.168.89.131)' can't be established.
ECDSA key fingerprint is SHA256:AJ/rhsl+I6zFOYitxSG1CuDMEos0Oue/u8co7cF5L0M.
ECDSA key fingerprint is MD5:75:eb:3c:52:df:9b:35:cb:b3:05:c4:1a:20:13:73:01.
Are you sure you want to continue connecting (yes/no)? slave02: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-slave02.out
yes
slave03: Warning: Permanently added 'slave03,192.168.89.131' (ECDSA) to the list of known hosts.
slave03: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-slave03.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
ECDSA key fingerprint is SHA256:AJ/rhsl+I6zFOYitxSG1CuDMEos0Oue/u8co7cF5L0M.
ECDSA key fingerprint is MD5:75:eb:3c:52:df:9b:35:cb:b3:05:c4:1a:20:13:73:01.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-secondarynamenode-slave01.out
[hadoop@slave01 sbin]$ jps
27734 Jps
27596 SecondaryNameNode
26894 NameNode
[hadoop@slave01 sbin]$ ./start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-resourcemanager-slave01.out
slave03: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-nodemanager-slave03.out
slave02: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-hadoop-nodemanager-slave02.out
[hadoop@slave01 sbin]$ jps
28080 Jps
27814 ResourceManager
27596 SecondaryNameNode
26894 NameNode
[hadoop@slave01 sbin]$
中间需要操作的直接按提示来,从jps命令显示的结果可以看出,NameNode和ResourceManager等都已经正常启动了,很欣慰啊。
(2)在slave02和slave03上执行jps命令
#slave02
[hadoop@slave02 hadoop]$ jps
12296 DataNode
13226 Jps
12446 NodeManager
[hadoop@slave02 hadoop]$
#slave03
[hadoop@slave03 hadoop]$ jps
12122 NodeManager
11978 DataNode
12796 Jps
[hadoop@slave03 hadoop]$可以看到DataNode和NodeManager都正常启动了。若没有成功启动,需要关掉slave01中的进程,找寻原因,我也出现该问题了,后来将三个服务器上/hadoop/tmp/dfs目录下的data文件夹删掉了,重新启动则成功了。当然视情况而定。
(3)查看hadoop运行管理界面
访问http://slave01:8088(默认8088端口,若被占用,请修改):
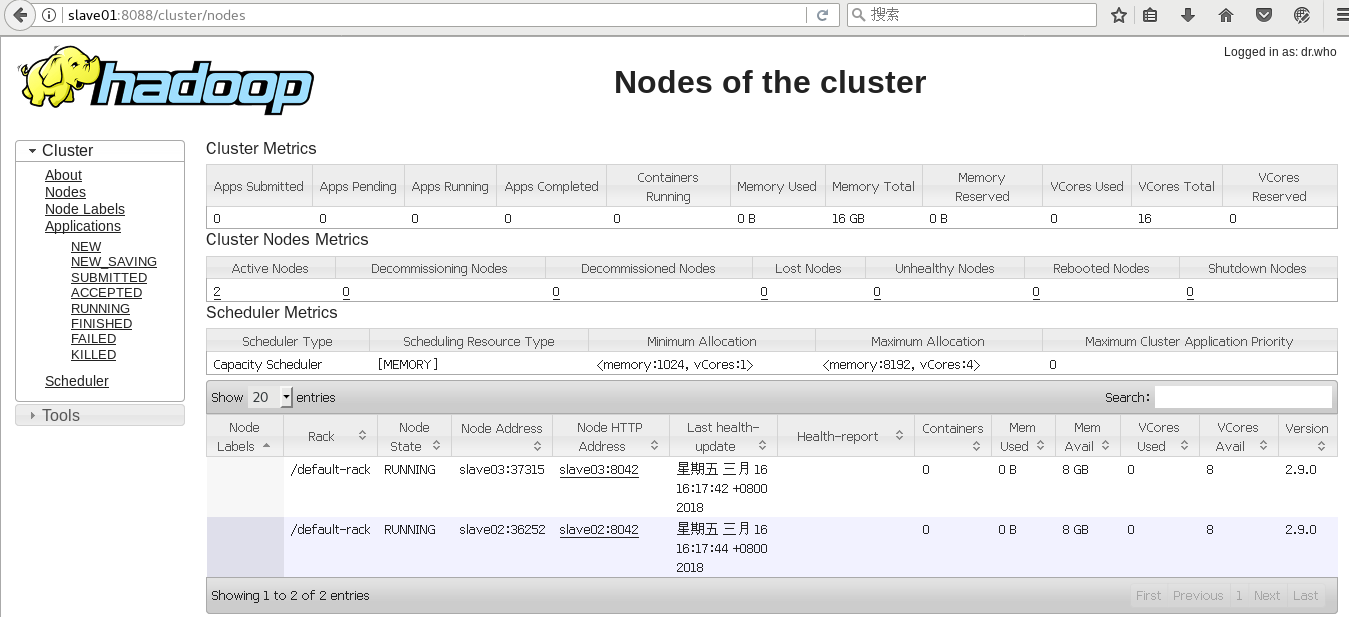
访问http://slave01:50070:
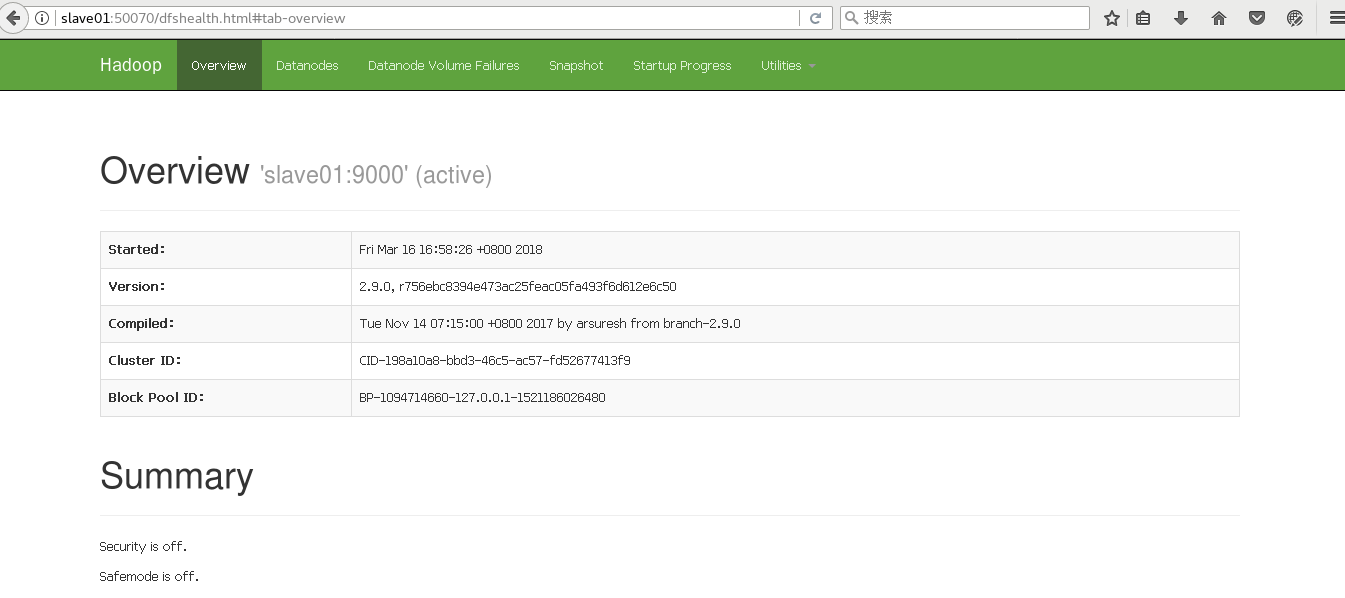
好了,现在Hadoop集群的搭建已经完成了,O(∩_∩)O。
文章来源:
Author:海岸线的曙光
link:https://my.oschina.net/u/3747963/blog/1636026