找寻一个简易的 Kindle 书摘管理方案
上学期,我购入了 Kindle 并决定将它离线使用。Kindle 的阅读体验确实一流,但是由于亚马逊生态的封闭,从 Kindle 导出书摘、笔记就有些困难。
书摘导出的困难
在阅读时的划线批注,存储在哪里呢?
将 Kindle 连接电脑后,观察挂载的硬盘目录,会发现书籍对应的 mobi 文件同目录下有一个同名的以 .sdr 结尾的文件夹,文件夹中有拓展名为 .mbs 和 .mbp1 的文件,这便是 Kindle 保存我们的阅读信息的地方,包括阅读时的划线、阅读位置、书签等各种信息。对于 mobi 以外的其他格式,这个文件的拓展名也不一样。
然而,这两个文件采用了 Kindle 专有的格式,用文本编辑器无法打开。论坛里有大佬编写了 KRDS 软件——用于这两个文件的解析器,可以将这些文件的内容解析为 json 数据。然而,经过尝试,解析得到的书摘(划线)只记录了「在书中的开始位置」和「在书中的结束位置」,而这些位置的地址格式也是 Kindle 的专有格式,是不可读的。
似乎,从 sdr 文件夹中读取和阅读时完全一致的数据,非常困难。
My Clippings.txt
在书中划线批注时,Kindle 还会将我们的划线批注,连同时间、书籍信息等内容,以特定的文本格式自动加入一个名为 My Clippings.txt 的文档中。这个文件在 Kindle 的根目录下 documents 文件夹里。在 Kindle 图书馆里,会显示为一本书,叫做「我的书摘」。
这个文本文件和上述实际存储我们书摘的 sdr 文件夹是独立的。Kindle 做的只是在我们添加书摘时,将内容的副本加到 txt 文档的末端。这意味着,当我们因为误划线等原因删除书摘,它仍然会停留在 txt 文档中;其中的书摘按照时间顺序排列;当我们修改书的作者等元信息,txt 中书摘记录的内容并不会修改。也就是说,这个文本文件失去了和书籍的耦合。这不是我想要的书摘管理方式。
既然这个 txt 是可读的,我们可以定期将它导入电脑管理。许多号称能导入、同步、管理 Kindle 书摘的软件,都是这么做的。
其他软件的解决方案
一个有名的简体中文 Kindle 网站是书伴网。它推出了书见,提供了 My Clippings.txt 书摘导入上传的功能。并且在导入的页面支持简单的编辑、去重等功能。然而,我使用的时候还是有几个小问题让我不太喜欢:
书摘解析器并不完美。比如不能正确处理 CRLF 和 LF 两种换行符的问题。 存在 bug,比如对一本书修改作者名后,如果存在两本书名、作者名都相同的书籍(重复书籍),不会自动合并。(这个 bug 一般人应该不会遇到,是因为我用 Calibre 管理 Kindle 书籍时,读书读到一半发现作者有误,修改了作者,后面的笔记记录的作者也修改了) 数据不能导出。我不相信任何网站能够长久存在。我希望导入的书摘数据能存到我的本地。另一个看起来不错的软件是 Knotes。它同样支持从 Kindle 等各种地方导入书摘。然而试用之后,还是有我不喜欢的点:
这是一个创业团队的产品,野心似乎不止于简单的书摘管理,功能比较繁多,大多是我用不到的。 UI 不太喜欢。不是我想要的风格。我只是想要一个简单的、UI 符合我审美的书摘管理器。而这两个软件中我最需要的功能就是解析、导入 My Clippings.txt。于是我就有了自己写一个的念头。
奇怪的格式
既然要自己写这样一个软件,首先是要能够解析 My Clippings.txt 文件。以上体验的两个软件,My Clippings.txt 的解析器都不是开源的。
这个文件内容大概是这样的:
平凡的世界 (路遥)
- 您在第 280 页(位置 #4283-4286)的标注 | 添加于 2023年5月19日星期五 下午1:11:48
勿容置疑,她是一个普普通通的人,她的思想、气质、感情,优点和缺点,都是属于普通人的。但普通人和出类拔萃的人一样,也有自己的欢乐和痛苦,只不过不为大多数人了解罢了。人们宁愿去关心一个蹩脚电影演员的吃喝拉撒和鸡毛蒜皮,而不愿了解一个普通人波涛汹涌的内心世界……
==========
邓小平时代 (傅高义)
- 您在位置 #388-390的标注 | 添加于 2023年7月4日星期二 下午6:18:24
当会谈结束后他们起身走向门口时,邓小平向麦理浩做了个手势,身高逾一米八的港督俯下身,听到这位身材只有一米五几的主人对他说:“你如果觉得统治香港不容易,那就来统治中国试试。”
==========
人类群星闪耀时 (斯蒂芬·茨威格)
- 您在第 172 页(位置 #2633-2637)的标注 | 添加于 2023年7月13日星期四 上午12:09:04
伟大的对决中,英雄虽死犹生,失败中的意志崛起,直抵无限高峰。因为偶然的成功和轻易的胜利只能点燃人的虚荣之心,却不能获得一个人在与不可战胜的强大命运的搏击中,因为覆灭而升华的高尚心灵。这类一切时代,一切悲剧中最伟大的杰作,时常刻画于诗人笔下又千百次地在生活中诞生。
==========
每两条书摘之间用多个等号组成的分割线隔开,每一条记录包含:
第一行:书名、作者。 第二行:摘录位置和时间。有的位置包含页码,有的不包含。 空行。 摘录内容。看起来,按照一定的模式可以将其转换为 json 格式。如果有这样一个解析器能够正确解析,实现书摘的管理器就没什么大问题了。
构建一个 npm 模块
上网搜索了一圈,在 Github 上找到了这个代码仓库,仓库里包含了作者自用的书摘管理器,其中这段代码是一个可用的解析器代码。但是,它只支持英文版的 My Clippings.txt。看来,我可以修改一下使之支持中文版。
很自然地,想要将其构建成一个 npm 模块方便使用。然而,之前我丝毫没有写 npm 模块的经历,连 node 都不太会用……好在,有万能的 GPT 来帮忙。
如何编写一个 npm 模块?请告诉我典型的目录结构,并给我一个示例代码。
如何发布一个 npm 模块?
如何引入并使用一个 npm 模块?
如何使模块兼容 TypeScript?
CommonJS 和 ES6 之类的标准有何区别?
……
(事实上,这基本上也是我第一次用 TypeScript 和 eslint……)
其实代码主要内容是很少的,无非就是按照上面奇怪的格式,先用等号分割每条记录,然后对每条记录分别解析书名、作者、页码、起止位置、时间戳、内容……只是正则表达式依然令人头疼(并且 GPT 似乎也不太懂)。
于是,这个适用于简体中文的 Kindle MyClippings.txt 解析器就大功告成啦。它可以解析一个字符串的内容,返回一个 JavaScript Object,包含每条书摘的具体内容。目前我测试的自己的书摘暂时没有遇到 bug。
下一步:成型的书摘管理软件
接下来是我正在开发的书摘管理软件。
还是决定基于 Next.js,然而如果要做在线部署的 Web 软件,则要考虑用户登录之类的操作,有些繁琐(我甚至考查了许多可以自托管的 SSO 软件,没有特别满意的)。于是我大胆决定:基于 Electron 开发桌面软件。
这又是一个完全没接触过的框架。还好,我们有 GPT。
如何基于 Next.js、TypeScript 创建一个 Electron 项目?请告诉我典型的目录结构,并给我一个示例代码。
基本上是用逻辑其实是仿照前面介绍的书见进行开发的。
开发一个桌面软件和开发一个 Web 软件的前端思路还是有差异的,毕竟是要我们用做网页的思路来做桌面软件。我能想到的就是针对窗口大小调整做出更详细的优化,并让所有 p 元素不可选择 🙃。
目前这个软件还在开发中。想了很久叫什么名字,最后还是取了直白的「BookNotes」。
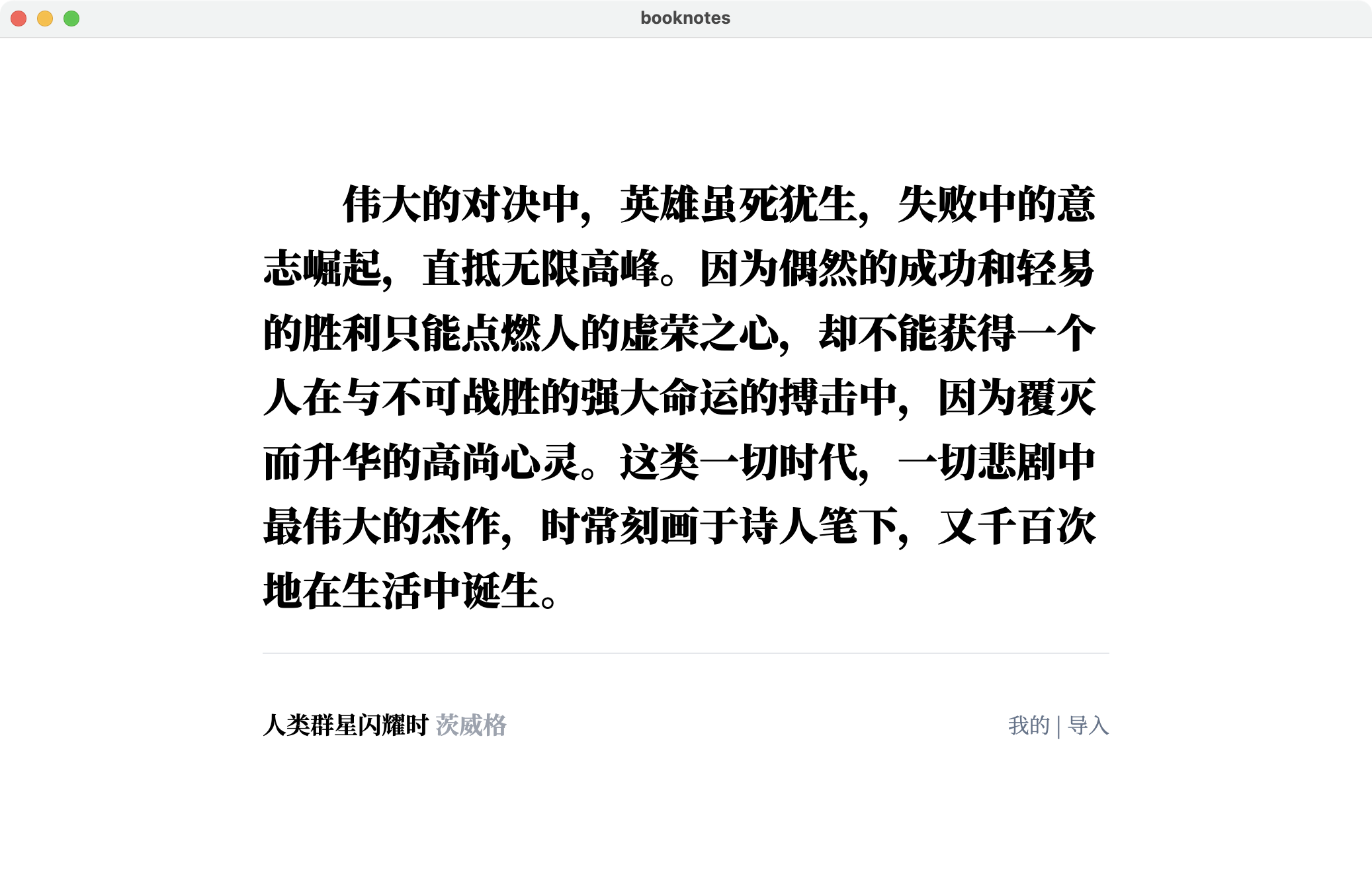
900 磅的思源宋体真的很好看!
在这里先挖个坑,等有空慢慢开发吧。
文章来源:
Author:me@skywt.cn
link:https://skywt.cn/blog/find-an-easy-kindle-extraction-management-solution/