java多线程——CAS
这是多线程系列第五篇,其他请关注以下:
java 多线程—线程怎么来的?
java多线程-内存模型
java多线程——volatile
java多线程——锁

关于无锁队列,网上有很多介绍了,我做一个梳理,从它是什么再到有哪些特性以及应用做一个总结,方便自己记录和使用。
本文主要内容:
非阻塞同步是什么 CAS是什么 CAS特性 无阻塞队列 ABA问题
一、非阻塞同步
互斥同步属于一种悲观的并发策略,总认为只要不去做正确的同步措施,肯定会出问题,无论共享数据是否真的会出现竞争,它都要进行加锁。
而基于冲突检测的乐观并发策略,是先进行操作,如果没有竞争,就操作成功了,如果有竞争,产生冲突了,就采用补救措施,常见的就是不断的重试。
CAS就是一种乐观并发策略,除了CAS以外,还有:
Test-and-Set(测试并设置),
Fetch-and-Increment(获取并增加),
Swap(交换),
LL/SC(加载链接/条件存储)
以上这些都需要硬件指令集的支持才具备原子性。比如在IA64、x86 CPU架构下可以通过cmpxchg指令完成CAS功能,而在ARM和PowerPC架构下,需要ldrex/strex指令来完成LL/SC的功能。
二、CAS是什么
cas全称为Compare-and-Swap(比较并交换),有3个操作数,分别是内存位置V、旧的的预期值A、新值B,那么当且仅当V符合旧的预期值A时,处理器用新值B更新V的值为B。并且这些处理过程有指令集的支持,因此看似读-写-改操作只是一个原子操作,所以不存在线程安全问题。我们看个cas的操作过程伪代码:
int value;
int compareAndSwap(int oldValue,int newValue){
int old_reg_value =value;
if (old_reg_value==old_reg_value)
value=newValue;
return old_reg_value;
}
当多个线程尝试使用CAS同时更新同一个变量的时候,只有其中一个线程能够更新变量的值。当其他线程失败后,不会像获取锁一样被挂起,而是可以再次尝试,或者不进行任何操作,这种灵活性就大大减少了锁活跃性风险。
jvm对CAS支持
jdk在1.5之前没有对cas的支持,从jdk1.5开始开始引入了底层的支持,目前在int、long和对象的引用上都公开了cas操作,主要有sum.misc.Unsafe 来包装,然后由虚拟机对这些方法做特殊处理。在支持cas的平台上,运行时将其编译为相应的机器指令,最坏情况下,如果不支持cas指令,jvm会使用自旋锁来代替。
目前java对cas支持的类主要在util.concurrent.atomic 包下面,具体的使用不在介绍了,比如,我们常见的AtomicInteger就是采用cas操作保证了int值改变的安全性。
三、CAS特性
我们知道采用锁对共享数据进行处理的话,当多个线程竞争的时候,都需要进行加锁,没有拿到锁的线程会被阻塞,以及唤醒,这些都需要用户态到核心态的转换,这个代价对阻塞线程来说代价还是蛮高的,那cas是采用无锁乐观方式进行竞争,性能上要比锁更高些才是,为何不对锁竞争方式进行替换?
要回答这个问题,我们先举个例子。
当你开车在上班高峰期的时候,如果通过交通信号灯来控制车流,可以实现更高的吞吐量,而环岛虽然无红绿灯让你等待,但你一圈不一定能绕出你先出去的那个路口,有时候可能得多走几圈,而在低拥堵的时候,环岛则能实现更高的吞吐量,你一次就可以成功,而红路灯反而效率低下了,即便人不多,你依然需要等待。
这个例子依然适应锁和cas的比较,在高度竞争的情况下,锁的性能将超过cas的性能,但在中低程度的竞争情况下,cas性能将超过锁的性能。多数情况下,资源竞争一般都不会那么激烈。
四、非阻塞无锁链表
我们参考一个ConcurrentLinkedQueue 的源码实现,来看下cas的应用。
ConcurrentLinkedQueue是一个基于链接节点的无界线程安全队列,它是个单向链表,每个链接节点都拥有一个当前节点的元素和下一个节点的指针。
Node<E> {
volatile E item;
volatile Node<E> next;
}它采用先进先出的规则对节点进行排序,当我们添加一个元素的时候,它会添加到队列的尾部(tail),当我们获取一个元素时,它会返回队列头部(head)的元素。tail节点和head节点方便我们快速定位最后一个和第一个元素。
我们看下添加一个元素的源码实现:
public boolean offer(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
//从tail执向的节点开始循环,查找尾部节点,然后插入,直到插入成功。
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) {
// p 是最后一个节点
if (p.casNext(null, newNode)) {
// 添加下一个节点成功之后,如果当前tail节点的next节点!=null,更新tail的指针指向newNode
// 如果==null,则不更新t
if (p != t)
casTail(t, newNode); // 更新tail节点指针指向newNode
return true;
}
// 没有竞争上cas的线程,继续循环
}
else if (p == q)
// 如果next节点指向自己,表示tail指针自引用了,当前只有head一个节点,下一个节点从head开始循环
p = (t != (t = tail)) ? t : head;
else
// 如果tail节点的next节点不为null,继续查找尾部节点(尾部节点的next==null)
p = (p != t && t != (t = tail)) ? t : q;
}
}
上述代码主要做了如下功能:
1、从tail指针指向的节点开始循环,查找尾节点,尾节点的特征是next为null。
2、如果当前节点的nextNode!=null,则继续查找nextNode的nextNode。
2、如果当前节点的nextNode==null,表明找到尾部节点,则添加newNode到尾部节点的nextNode。
3、更新tail指针,一般指向最新尾节点
4、如果tail节点nextNode==null,则不更新,表明上一次已经指向最新的尾node。
5、如果!=null,则更新为newNode,2次插入操作更新一次
示图:
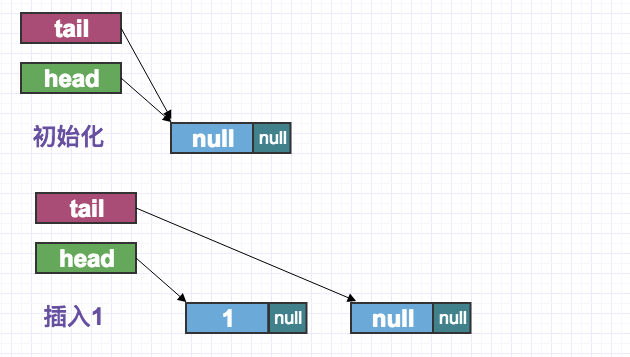
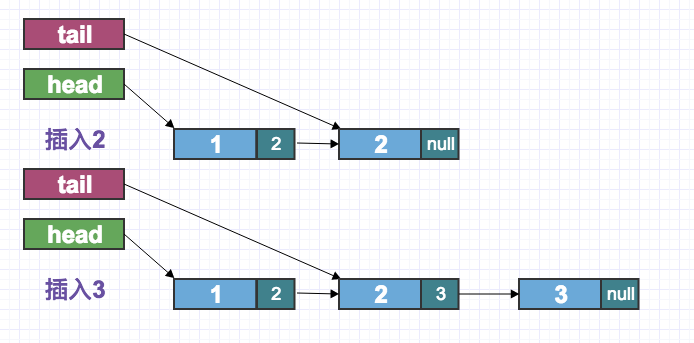
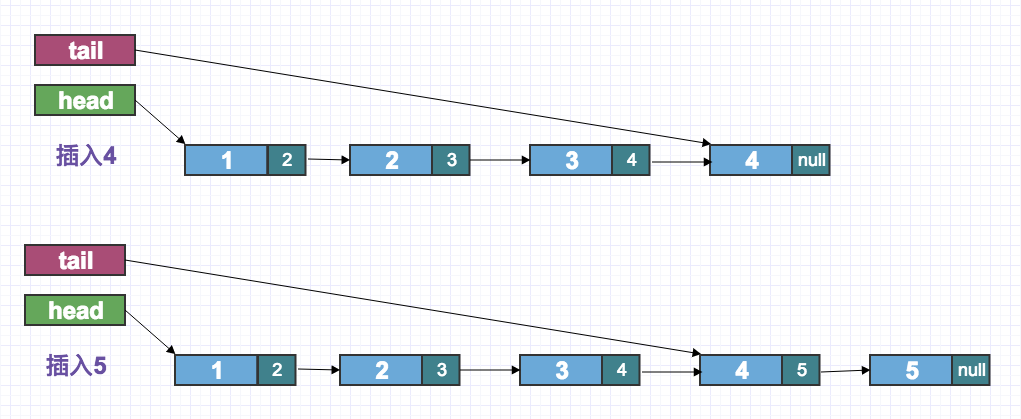
上面的代码算法过于复杂,简化如下:
while (true){
//添加尾节点的next节点,成功之后,更新tail的指针指向最新尾节点
if (tail.casNext(null, newNode)) {
casTail(tail, newNode);
return true;
}
}
为何要2次插入node之后,再更新tail的指针?
1、减少tail的写入次数,从而减小write开销
2、tail的读次数增加不会影响性能,虽然增加一次循环开销,但相对于写来说并不大。
3、tail加快入队效率,不会每次入队都从head开始找尾部node。
有两次CAS操作,如何保证一致性?
1、如果第一个cas更新成功,第二个失败,那么对了tail会出现不一致的情况。而且即便是都更新成功了,在执行两个cas之间,仍然可能有另外一个线程会访问这个队列,那么如何保证这种多线程情况下不会出错。
2、对于第一个问题,即便tail更新失败,上述代码也会循环的找到真正的尾节点,在这里不是强制要求以tail为尾节点,它只是一个靠近尾节点的指针。
3、第二种情况,如果线程B抵达时候,发现线程A正在执行更新,那么B线程会通过反复循环来检查队列的状态,直到A完成更新,B线程又拿到了nextNode最新信息,添加新的node,从而使两个线程不会相互干扰。
以上就是ConcurrentLinkedQueue无阻塞链表的基本思想,我们可以看到如何运用cas来进行共享数据进行更新,以及如何提升效率。源码采用jdk1.8。
五、ABA 问题
尽快CAS看起来很完美,但从语义上来说并不是完美的,存在这样一个逻辑漏洞:
如果一个变量V初次读取的时候是A值,并且在准备赋值的时候检查到它依然是A值,那么我们就认定它没有改变过。如果在这期间它的值被改为B,后来又改为A,那么CAS就会误认为它从来没有被改变过,这个漏洞也被成为“ABA”问题。
在c的内存管理机制中广泛使用的内存重用机制,如果是cas更新的是指针,机会出现一些指针错乱的问题。常见的ABA问题解决方式,就是在更新的时候增加一个版本号,每次更新之后版本号+1,从而保证数据一致。
不过大部分情况下ABA问题都不会影响到程序的正确性,如果需要解决,可以特殊考虑下,或者采用传统的互斥同步会更好。
-----------------------------------------------------------------------------
想看更多有趣原创的技术文章,扫描关注公众号。
关注个人成长和游戏研发,推动国内游戏社区的成长与进步。

文章来源:
Author:wier
link:https://my.oschina.net/u/1859679/blog/1539630