简单的Spark+Mysql整合开发
今天简单说下Spark和Mysql的整合开发,首先要知道:在Spark中提供了一个JdbcRDD类,该RDD就是读取JDBC中的数据并转换成RDD,之后我们就可以对该RDD进行各种的操作,该类的构造函数如下:
JdbcRDD[T: ClassTag](
sc: SparkContext,
getConnection: () => Connection,
sql: String,
lowerBound: Long,
upperBound: Long,
numPartitions: Int,
mapRow: (ResultSet) => T = JdbcRDD.resultSetToObjectArray _)参数:
(1)getConnection 返回一个已经打开的结构化数据库连接,JdbcRDD会自动维护关闭。
(2)sql 是查询语句,此查询语句必须包含两处占位符?来作为分割数据库ResulSet的参数,例如:"select title, author from books where ? < = id and id <= ?"
(3)lowerBound, upperBound, numPartitions 分别为第一、第二占位符,partition的个数。例如,给出lowebound 1,upperbound 20, numpartitions 2,则查询分别为(1, 10)与(11, 20)
(4)mapRow 是转换函数,将返回的ResultSet转成RDD需用的单行数据,此处可以选择Array或其他,也可以是自定义的case class。默认的是将ResultSet 转换成一个Object数组。
下面是动手实践,我的开发环境是:
虚拟机CentOs7系统,IDEA,JDK8,Scala 2.11,Spark 2.0.1,一些基本环境问题这里就不再叙述了。
本人使用的是maven,创建maven项目,初始化并添加依赖,下面是pom.xml:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>JdbcRdd</groupId>
<artifactId>Demo</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2018</inceptionYear>
<properties>
<scala.version>2.11.8</scala.version>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.0.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.25</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
新建scala的Object类,如下:
package JdbcRdd
import java.sql.DriverManager
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.JdbcRDD
object SparkToJdbc {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("mysql").setMaster("local")
val sc = new SparkContext(conf)
val rdd = new JdbcRDD(
sc,()=>{
Class.forName("com.mysql.jdbc.Driver").newInstance()
DriverManager.getConnection("jdbc:mysql://连接的IP:3306/连接的数据库名", "用户名", "密码")
},
"SELECT CATEGORY FROM nyw_knowledges WHERE COMPANY_CODE >= ? AND COMPANY_CODE <= ?",
1000, 1200, 3,
r => r.getString(1)).cache()
val rd = rdd.filter(_.contains("咨询")).count()
println(rd)
sc.stop()
}
}
这里基本的代码就这些,连接数据库后对表进行操作。
注意:这里可能会出现几个问题,需要慎重处理:
(1)内存问题:如果内存不够,则需要重新设置,本人使用的是运行时配置:
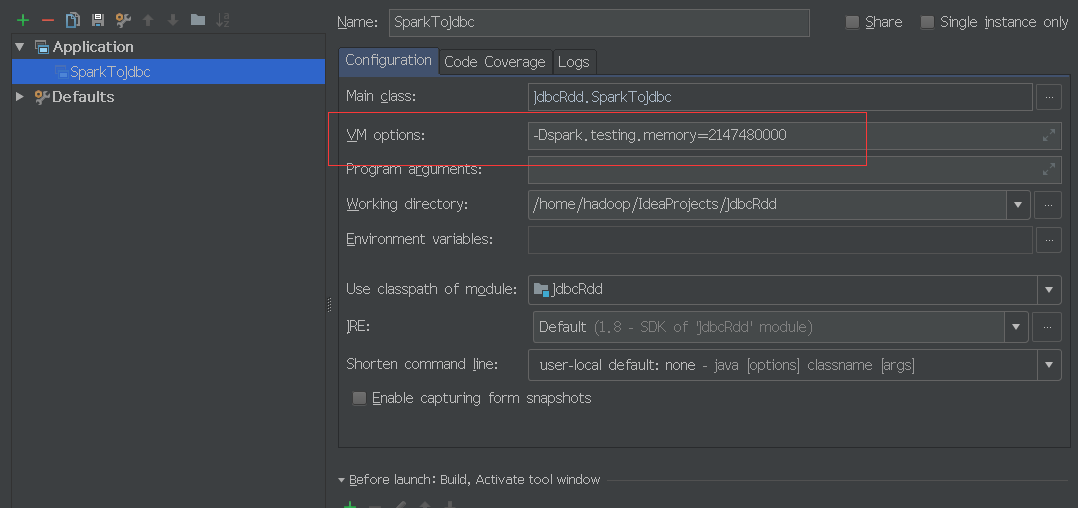
也可以用另一种方式,在代码中配置,
可参考:http://blog.csdn.net/qingyang0320/article/details/50787550。
(2)数据库访问限制问题
报错:java.sql.SQLException: null, message from server: “Host ‘xxx’ is not allowed to connect,该问题是由于本机的访问权限未开放,需要进行设置。
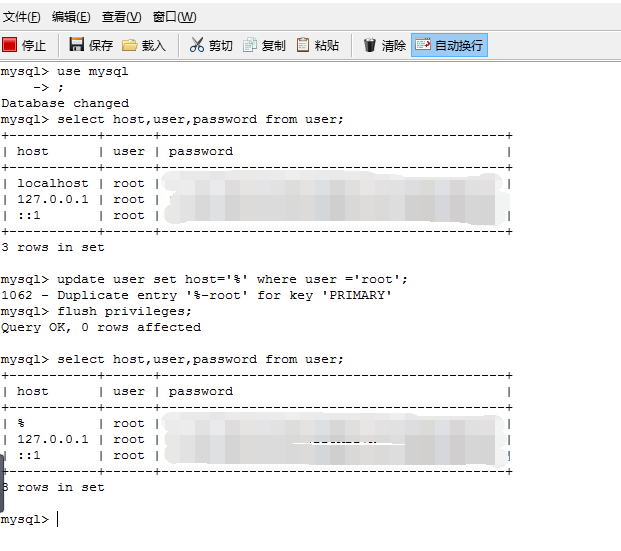
可参考:http://blog.csdn.net/xionglangs/article/details/50385057。
(3)mysql Driver依赖未添加报错
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.25</version>
</dependency>结果:
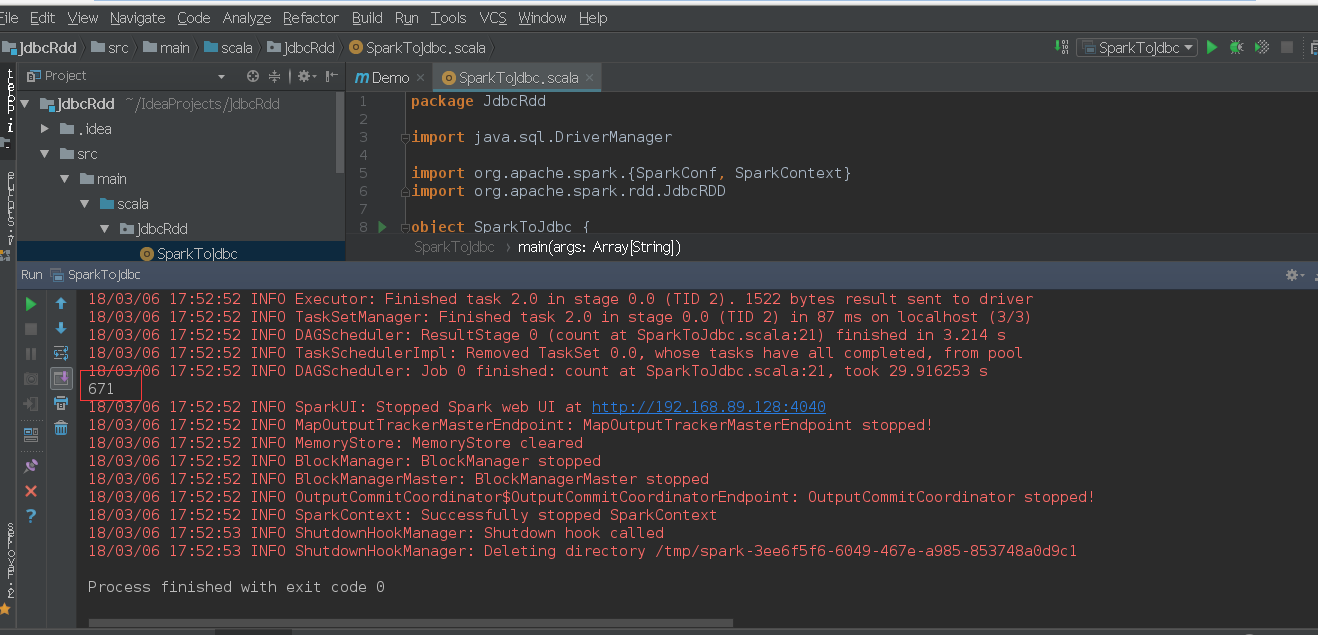
通过访问Spark web UI的地址:localhost:4040能够清楚的查看具体的spark参数,大功告成。
文章来源:
Author:海岸线的曙光
link:https://my.oschina.net/u/3747963/blog/1630593