rCore Tutorial Chapter 1 练习
这是 rCore Tutorial Book 第一章「应用程序与基本执行环境」的练习。
课后练习
编程题
Program 1
1. 实现一个 linux 应用程序 A,显示当前目录下的文件名。
#include <dirent.h>
#include <stdio.h>
int main() {
DIR *dir = opendir(".");
struct dirent *entry;
while ((entry = readdir(dir))) {
printf("%s\n", entry->d_name);
}
return 0;
}
相关库的用法:
dirent.h 这个库中,定义了DIR 数据类型,表示一个目录流。同时还定义了一个叫做 dirent 的数据类型,是一个结构体,其中一个成员是 char d_name[],即目录的名称。
opendir 函数打开一个目录流,返回的正是 DIR 对象。
readdir 函数以一个 DIR 对象为参数,返回一个 dirent 类型结构体,它表示传入的 DIR 指针指向的条目;同时,会将指针指向下一个条目。
Program 2
2. 实现一个 Linux 应用程序 B,能打印出调用栈链信息。
(前置知识:C 语言中内联汇编语句 asm 的用法)
这里在 x86_64 环境下运行。我们直接内联汇编命令,将栈底指针寄存器 rbp 取出来,并不断根据寄存器的内容追溯上一个栈帧的 rbp。(注意我们是 64 位环境,所以最好使用 64 位的 rbp 而不是 ebp)
需要注意的是,根据实践,第一个栈帧的 rbp 指向的是 0x1 而不是 0x0。while 循环何时停止需要根据此判断。
编写输出栈信息的函数如下:
void print_call_stack_info() {
unsigned long long stack_ptr;
asm ("mov %%rbp, %0" : "=r" (stack_ptr));
printf("== BEGIN CALL STACK INFO\n");
while (stack_ptr != 0x1) {
printf(" == %p\n", (void*)stack_ptr);
stack_ptr = *((unsigned long long*)stack_ptr);
}
printf("== END CALL STACK INFO\n");
}
递归调用的函数能让我们最直观地体会到栈的变化。编写好如上函数之后,我们来编写一个递归计算阶乘的函数,并让程序计算 5 的阶乘:
int fact(int x){
printf("Calling fact(%d)\n", x);
print_call_stack_info();
if (x == 0) return 1;
return fact(x-1) * x;
}
int main() {
print_call_stack_info();
printf("5! = %d\n", fact(5));
return 0;
}
编译运行,程序会在每次调用 fact 时输出栈信息。可以看到在 fact(0) 中调用 print_call_stack_info() 有 8 行输出(也就是有 8 个栈帧),在 fact(5) 中则是 3 行输出(3 个栈帧)。这表示从 fact(5) 递归调用到 fact(0),创建了 5 个栈帧。每个栈帧的大小是 0x20。
Calling fact(5)
== BEGIN CALL STACK INFO
== 0x7ffdb04f1060
== 0x7ffdb04f1080
== 0x7ffdb04f1090
== END CALL STACK INFO
...
Calling fact(0)
== BEGIN CALL STACK INFO
== 0x7ffdb04f0fc0
== 0x7ffdb04f0fe0
== 0x7ffdb04f1000
== 0x7ffdb04f1020
== 0x7ffdb04f1040
== 0x7ffdb04f1060
== 0x7ffdb04f1080
== 0x7ffdb04f1090
== END CALL STACK INFO
5! = 120
Program 3
3. 实现一个基于 rcore/ucore tutorial 的应用程序 C,用 sleep 系统调用睡眠 5 秒(in rcore/ucore tutorial v3: Branch ch1)
(超纲了,不会)
问答题
Problem 1
1. 应用程序在执行过程中,会占用哪些计算机资源?
CPU:应用程序的指令由 CPU 执行。 RAM:指令和数据存在内存中。 磁盘:程序可能进行磁盘读写操作。当 RAM 不足时也可能占用磁盘上的 swap 分区。 网络:使用网络的程序可能通过网卡进行网络通信。 输入输出设备:程序通过鼠标、键盘等设备获得输入,通过显示器、扬声器等设备实现输出。 GPU:某些程序可能使用 GPU 进行图形渲染。Problem 2
2. 请用相关工具软件分析并给出应用程序 A 的代码段/数据段/堆/栈的地址空间范围。
查看代码段、数据段信息:
为了查看完整代码段和数据段信息,需要对程序进行静态编译。否则,只能看到共享库的代码段和数据段信息,无法看到程序本身的代码段和数据段信息。
使用 gcc 对 ls.c 文件进行静态编译,然后使用 readelf 工具查看地址空间:
gcc -static ls.c -o ls_static
readelf --headers ./ls
输出如下信息:
节头:
[号] 名称 类型 地址 偏移量
大小 全体大小 旗标 链接 信息 对齐
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
...
[ 7] .text PROGBITS 0000000000401100 00001100
0000000000076e3f 0000000000000000 AX 0 0 64
...
[10] .rodata PROGBITS 0000000000479000 00079000
000000000001bca4 0000000000000000 A 0 0 32
...
[20] .data PROGBITS 00000000004a40c0 000a40c0
00000000000019f8 0000000000000000 WA 0 0 32
...
[24] .bss NOBITS 00000000004a6280 000a6270
0000000000005800 0000000000000000 WA 0 0 32
...
可以看到:
代码段地址空间.text 的虚拟地址是从 0x401100 到 0x477f3e。
数据段的几个地址空间:
.rodata 段地址是 0x479000 到 0x494ca4。
.data 段由 0x4a40c0 到 0x4a5ab8。
.bss 段由 4a6280 到 0x4aba80。
查看堆栈信息:
堆栈是程序运行时由 OS 内核分配的一段内存,所以我们需要在程序运行时查看。
首先在程序最后一行加上无限循环的 for 语句,使其能一直保持运行,方便我们查看:
for (;;);
然后将该程序命名为 myls(以在 grep 时区分系统自带的 ls),新开一个 tmux session(或者 screen),将其放在后台运行:
tmux new -s test
./myls
# 按下 Ctrl + A,再按下 D 即可 detach 当前 session
回到 tmux 之外的 shell 后,我们查看 myls 这个进程的信息:
ps -aux | grep myls
skywt 203187 100 0.0 2460 904 pts/1 R+ 21:00 0:05 ./myls
skywt 203257 0.0 0.0 6560 2264 pts/0 S+ 21:00 0:00 grep --color=auto myls
可以看到正在运行的 myls 进程的 PID 是 203187。
此时查看 /proc/203187/maps 可以看到堆栈空间的分布:
cat /proc/203187/maps
55ad32a2c000-55ad32a2d000 r--p 00000000 103:04 555500 /home/skywt/labs/rCore/homework/myls
...
55ad3438a000-55ad343ab000 rw-p 00000000 00:00 0 [heap]
7f8045692000-7f8045695000 rw-p 00000000 00:00 0
...
7ffe7709a000-7ffe770bb000 rw-p 00000000 00:00 0 [stack]
...
/proc/[pid]/maps 是一个特殊的文件,用于显示某个进程的内存映射信息,其中包含了该进程的内存分段(或称为内存映射)的详细信息。
每一行 /proc/[pid]/maps 文件中的内容描述了一个内存分段的起始地址、结束地址、访问权限、偏移量、设备号、节点号等信息。这些信息可以帮助我们了解进程的内存使用情况。文件格式如下:
<start_address>-<end_address> <perms> <offset> <dev> <inode> <pathname>
其中:
<perms> 表示内存分段的访问权限,如 r(可读)、w(可写)、x(可执行)等。
<offset> 表示该内存分段在文件中的偏移量,如果不是文件映射则为 0。
<dev> 表示设备号,通常是一个主设备号和次设备号的组合。
<inode> 表示节点号,对于文件映射,表示文件在文件系统中的索引节点号。
<pathname> 表示映射到内存中的文件路径,如果没有映射文件则为 [anon]。
可以看到,堆([heap])的内存地址是 55ad3438a000-55ad343ab000,栈([stack])的内存地址是 7ffe7709a000-7ffe770bb000。
Problem 3
3. 请简要说明应用程序与操作系统的异同之处。
异: 应用程序一般运行在操作系统上;操作系统一般运行在裸机(bare-metal)环境(或虚拟机模拟的硬件环境)中。 应用程序一般面向用户;而操作系统(内核)一般并不面向用户,而是面向应用程序。 应用程序无法自由使用计算的资源,只有对资源部分的访问权限;操作系统则可以自由支配计算机资源,对资源具有完全的访问权限。 应用程序一般不关注计算机底层的硬件细节,但是操作系统需要关注。 编写应用程序一般不需要编写汇编代码,但是编写一个操作系统必须使用部分汇编代码。 同: 都是运行在计算机上的程序。操作系统可以视为一种特殊的应用程序。 都一般以二进制文件的形式保存在磁盘中。Problem 4
4. 请基于 QEMU 模拟 RISC—V 的执行过程和 QEMU 源代码,说明 RISC-V 硬件加电后的几条指令在哪里?完成了哪些功能?
在 QEMU 源码中可以找到「上电」的时候刚执行的几条指令,如下:
uint32_t reset_vec[10] = {
0x00000297, /* 1: auipc t0, %pcrel_hi(fw_dyn) */
0x02828613, /* addi a2, t0, %pcrel_lo(1b) */
0xf1402573, /* csrr a0, mhartid */
#if defined(TARGET_RISCV32)
0x0202a583, /* lw a1, 32(t0) */
0x0182a283, /* lw t0, 24(t0) */
#elif defined(TARGET_RISCV64)
0x0202b583, /* ld a1, 32(t0) */
0x0182b283, /* ld t0, 24(t0) */
#endif
0x00028067, /* jr t0 */
start_addr, /* start: .dword */
start_addr_hi32,
fdt_load_addr, /* fdt_laddr: .dword */
0x00000000,
/* fw_dyn: */
};
完成的工作是:
读取当前的 Hart ID CSR mhartid 写入寄存器 a0。 (我们还没有用到:将 FDT (Flatten device tree) 在物理内存中的地址写入 a1)。 跳转到 start_addr ,在我们实验中是 RustSBI 的地址。Problem 5
5. RISC-V 中的 SBI 的含义和功能是啥?
RISC-V SBI 官方文档
RISC-V 处理器有三种状态(特权级别),通过存储在 Control and Status Register CSR 中的特权位来控制:
机器模式(M 态):用于执行处理器级别任务 监管模式(S 态):用于执行 OS 内核代码相关任务,受限的系统级操作 用户模式(U 态):用于执行普通应用程序RISC-V SBI(Supervisor Binary Interface)是一套规范,定义了在 S 态下 OS 和硬件之间的接口。例如系统调用、中断控制接口、内存访问接口、I/O 设备访问接口等。
通过这些接口,OS 可以与硬件进行交互。当我们编写操作系统内核时,我们通过 SBI 规定的接口与模拟的硬件进行交互(如读入、输出字符等操作),而不是直接操作硬件。
SBI 相当于硬件和 OS 内核之间的一层,对硬件进行抽象。
Problem 6
6. 为了让应用程序能在计算机上执行,操作系统与编译器之间需要达成哪些协议?
程序库、依赖库等文件信息:需要约定好 OS 中各种库存放的位置,以方便应用程序调用。 二进制文件格式协议:需要约定可执行文件以什么格式存储,如 ELF(Executable and Linkable Format)就是一种常见的格式。 系统调用接口协议:要约定应用如何使用各种系统调用,在编译时写入对应操作系统的相关代码。 内存管理协议:需要约定内存管理的规范,编译器需要获知应用程序运行时分配得到的内存地址范围等信息。 进程管理协议:需要约定进程管理的模型,编译器需要据此来生成汇编代码控制应用的运行、发起子进程等等。 文件系统协议:需要约定应用程序如何访问文件系统,编译器通过约定的方式生成汇编代码对文件系统进行访问。 异常处理协议:需要约定如何处理应用程序运行时出现的各种异常。Problem 7
7. 请简要说明从 QEMU 模拟的 RISC-V 计算机加电开始运行到执行应用程序的第一条指令这个阶段的执行过程。
加电开始运行后,QEMU 的启动流程:
Step1:PC 初始化为 0x1000,执行一些指令后跳转到 0x80000000,进入第二阶段。 Step2:载入从 0x80000000 开始的 bootloader,这里就是 RustSBI(实验目录/bootloader/ 下的 rustsbi-qemu.bin 文件)。RustSBI 进行一些硬件(如串口)初始化,并通过 mret 使 PC 跳转到 0x80200000,即内存起始地址。
Step3:载入 0x80200000 开始的 OS 内核镜像,正式进入 OS 内核。内核进行部分初始化(如内存管理、进程初始化等),通过 sret 跳转到应用程序的第一行开始执行。
Problem 8
8. 为何应用程序员编写应用时不需要建立栈空间和指定地址空间?
应用程序访问的栈空间和地址空间需要由操作系统内核负责分配。对内存的访问需要通过 MMU 的地址翻译,使用的栈空间需要操作系统进行分配和管理。
程序员编写应用程序时,无需考虑操作系统底层的栈分配和地址空间分配,只需要使用操作系统、编译器等共同提供的「变量」、「函数」等抽象。这种设计大大方便了应用程序开发人员的软件开发。
Problem 9
9. 现代的很多编译器生成的代码,默认情况下不再严格保存/恢复栈帧指针。在这个情况下,我们只要编译器提供足够的信息,也可以完成对调用栈的恢复。
我们可以手动阅读汇编代码和栈上的数据,体验一下这个过程。例如,对如下两个互相递归调用的函数:
void flip(unsigned n) {
if ((n & 1) == 0) {
flip(n >> 1);
} else if ((n & 1) == 1) {
flap(n >> 1);
}
}
void flap(unsigned n) {
if ((n & 1) == 0) {
flip(n >> 1);
} else if ((n & 1) == 1) {
flap(n >> 1);
}
}
在某种编译环境下,编译器产生的代码不包括保存和恢复栈帧指针 fp 的代码。以下是 GDB 输出的本次运行的时候,这两个函数所在的地址和对应地址指令的反汇编,为了方便阅读节选了重要的控制流和栈操作(省略部分不含栈操作):
(gdb) disassemble flap
Dump of assembler code for function flap:
0x0000000000010730 <+0>: addi sp,sp,-16 // 唯一入口
0x0000000000010732 <+2>: sd ra,8(sp)
...
0x0000000000010742 <+18>: ld ra,8(sp)
0x0000000000010744 <+20>: addi sp,sp,16
0x0000000000010746 <+22>: ret // 唯一出口
...
0x0000000000010750 <+32>: j 0x10742 <flap+18>
(gdb) disassemble flip
Dump of assembler code for function flip:
0x0000000000010752 <+0>: addi sp,sp,-16 // 唯一入口
0x0000000000010754 <+2>: sd ra,8(sp)
...
0x0000000000010764 <+18>: ld ra,8(sp)
0x0000000000010766 <+20>: addi sp,sp,16
0x0000000000010768 <+22>: ret // 唯一出口
...
0x0000000000010772 <+32>: j 0x10764 <flip+18>
End of assembler dump.
启动这个程序,在运行的时候的某个状态将其打断。此时的 pc, sp, ra 寄存器的值如下所示。此外,下面还给出了栈顶的部分内容。(为阅读方便,栈上的一些未初始化的垃圾数据用 ??? 代替。)
(gdb) p $pc
$1 = (void (*)()) 0x10752 <flip>
(gdb) p $sp
$2 = (void *) 0x40007f1310
(gdb) p $ra
$3 = (void (*)()) 0x10742 <flap+18>
(gdb) x/6a $sp
0x40007f1310: ??? 0x10750 <flap+32>
0x40007f1320: ??? 0x10772 <flip+32>
0x40007f1330: ??? 0x10764 <flip+18>
根据给出这些信息,调试器可以如何复原出最顶层的几个调用栈信息?假设调试器可以理解编译器生成的汇编代码。
pc 寄存器的值(0x10752)指向了当前正在执行的指令地址,即 flip 函数的入口地址。这意味着当前的调用栈帧对应于 flip 函数的调用栈帧。 sp 寄存器的值(0x40007f1310)指向了当前栈帧的栈顶地址,即栈的最高地址。这意味着 flip 函数的栈帧在这个地址以下,而最顶层的调用栈信息应该在这个栈帧中。 ra 寄存器的值(0x10742)指向了 flap 函数的地址,它是 flip 函数的调用者。这意味着 flip 函数在执行时调用了 flap 函数,所以 flip 函数的栈帧应该保存了 flap 函数的返回地址。 根据反汇编信息,可以看到 flip 函数的栈帧在入口处(0x10752)保存了 ra 寄存器的值(0x10742),即 flap 函数的返回地址。 根据栈上的数据(0x40007f1310)可以看到栈帧中保存了一些未初始化的垃圾数据,而根据反汇编信息,栈帧的大小为 16 字节(0x10),因此可以通过栈顶地址向下偏移 16 字节,找到栈帧中保存的上一层调用栈帧的信息。实验练习
实验作业:彩色化 LOG
在 logging.rs 中的如下代码提供彩色 LOG 输出功能:
use log::{self, Level, LevelFilter, Log, Metadata, Record};
struct SimpleLogger;
impl Log for SimpleLogger {
fn enabled(&self, _metadata: &Metadata) -> bool {
true
}
fn log(&self, record: &Record) {
if !self.enabled(record.metadata()) {
return;
}
let color = match record.level() {
Level::Error => 31, // Red
Level::Warn => 93, // BrightYellow
Level::Info => 34, // Blue
Level::Debug => 32, // Green
Level::Trace => 90, // BrightBlack
};
println!(
"\u{1B}[{}m[{:>5}] {}\u{1B}[0m",
color,
record.level(),
record.args(),
);
}
fn flush(&self) {}
}
pub fn init() {
static LOGGER: SimpleLogger = SimpleLogger;
log::set_logger(&LOGGER).unwrap();
log::set_max_level(match option_env!("LOG") {
Some("ERROR") => LevelFilter::Error,
Some("WARN") => LevelFilter::Warn,
Some("INFO") => LevelFilter::Info,
Some("DEBUG") => LevelFilter::Debug,
Some("TRACE") => LevelFilter::Trace,
_ => LevelFilter::Off,
});
}
可以看到,在 init() 函数中,程序根据传入的 LOG 环境变量的值(可能为 ERROR、WARN 等)设置了 LevelFilter。当进行输出时调用 log 函数,根据输出的记录类型选择不同的颜色。
在 main.rs 中如下代码调用了彩色输出:
logging::init();
//...
trace!(
"[kernel] .text [{:#x}, {:#x})",
stext as usize,
etext as usize
);
debug!(
"[kernel] .rodata [{:#x}, {:#x})",
srodata as usize, erodata as usize
);
info!(
"[kernel] .data [{:#x}, {:#x})",
sdata as usize, edata as usize
);
warn!(
"[kernel] boot_stack top=bottom={:#x}, lower_bound={:#x}",
boot_stack_top as usize, boot_stack_lower_bound as usize
);
error!("[kernel] .bss [{:#x}, {:#x})", sbss as usize, ebss as usize);
在运行我们的操作系统内核时传递 LOG 参数,设定输出级别,如设定为 trace 输出从 trace 到 error 的全部级别:
make run LOG=trace
可以看到终端彩色的输出:
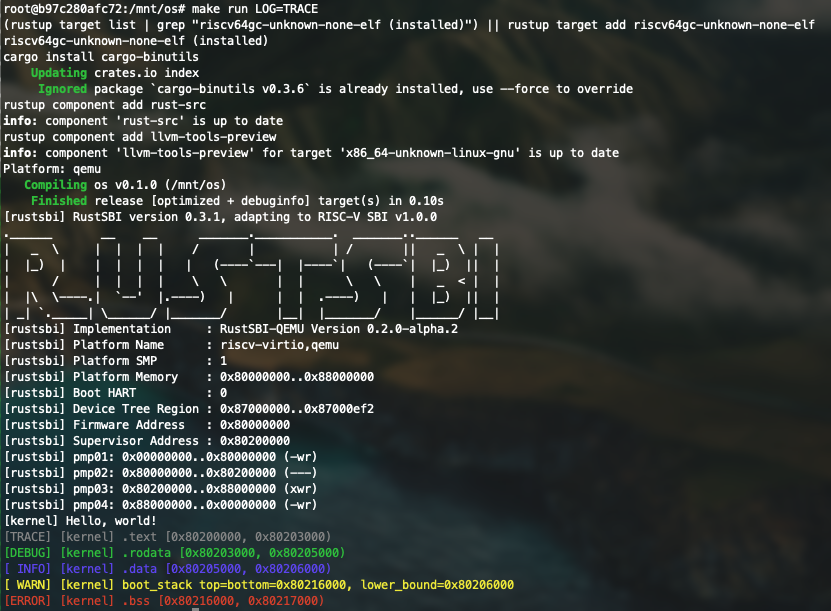
问答作业
请学习 gdb 调试工具的使用(这对后续调试很重要),并通过 gdb 简单跟踪从机器加电到跳转到 0x80200000 的简单过程。只需要描述重要的跳转即可,只需要描述在 qemu 上的情况。
由于我们的内核运行在 QEMU 里,我们没法直接通过原生的 gdb 像调试寻常的程序一样对它进行调试。不过,QEMU 提供了一些接口,可以通过网络(1234 端口)与 QEMU 之外的 gdb 对接(这个功能设计之初是为了方便网络调试),在 os/Makefile 里,已经为我们写好了使用 gdb 开启调试的命令。
由于我使用 docker 运行本实验的环境,在容器中开启 tmux 并不方便(使用预置的 make debug 会卡住)。但是,我们可以在容器外的多个终端都进入容器,等同于在容器内用了 tmux。
进行了 make docker 建立了 docker 环境之后,再开一个终端(可以在容器外用 tmux),同时进入相应的容器:
docker exec -it <container_name> /bin/bash
在容器内,根据这段介绍下载 Risc-V GCC 工具链。为了使用 riscv64-unknown-elf-gdb。方便起见,我们直接将解压后 bin 目录下的可执行文件复制到 os 目录下,然后修改一下 Makefile,将第 75 行改为运行当前目录下的 riscv64-unknown-elf-gdb 可执行文件:
gdbclient:
@./riscv64-unknown-elf-gdb -ex 'file $(KERNEL_ELF)' -ex 'set arch riscv:rv64' -ex 'target remote localhost:1234'
然后在一个终端里 make gdbserver,另一个终端里 make gdbclient(两个终端都在容器内,等同于 tmux),就可以开始调试啦。
(gdb) x/10i $pc
=> 0x1000: auipc t0,0x0
0x1004: addi a2,t0,40
0x1008: csrr a0,mhartid
0x100c: ld a1,32(t0)
0x1010: ld t0,24(t0)
0x1014: jr t0
0x1018: unimp
0x101a: 0x8000
0x101c: unimp
0x101e: unimp
可以看到 QEMU 启动后,PC 初始化为 0x1000。查看前几条指令,与我们之前看到的 QEMU 源码中的相关内容一致。0x1018 及之后似乎就不是指令了,所以这一部分就是 QEMU 启动的 Step 1,最后由 0x1014 这一行跳转到 0x80000000。
我们逐步运行这个程序,可以发现在跳转之前,t0 寄存器被设置为 0x80000000。
(gdb) si
0x0000000000001004 in ?? ()
(gdb) si
0x0000000000001008 in ?? ()
(gdb) si
0x000000000000100c in ?? ()
(gdb) si
0x0000000000001010 in ?? ()
(gdb) p/x $t0
1 = 0x80000000
(gdb) si
0x0000000080000000 in ?? ()
根据之前学习的 QEMU 启动流程,跳转到 0x80000000 之后进入了 bootloader,在我们的程序中也就是 RustSBI。在其中进行初始化之后,程序应该会跳转到 0x80200000 进入我们的 OS 内核。
在 0x80200000 打上断点,输入 c 让程序运行至停留在这条指令,可以看到内核的最初几行代码:
(gdb) b *0x80200000
Breakpoint 1 at 0x80200000
(gdb) c
Continuing.
Breakpoint 1, 0x0000000080200000 in stext ()
(gdb) x/10i $pc
=> 0x80200000 <stext>: auipc sp,0x16
0x80200004 <stext+4>: mv sp,sp
0x80200008 <stext+8>: auipc ra,0x0
0x8020000c <stext+12>: jalr 8(ra)
0x80200010 <os::rust_main>: addi sp,sp,-160
0x80200012 <os::rust_main+2>: sd ra,152(sp)
0x80200014 <os::rust_main+4>: sd s0,144(sp)
0x80200016 <os::rust_main+6>: sd s1,136(sp)
0x80200018 <os::rust_main+8>: sd s2,128(sp)
0x8020001a <os::rust_main+10>: sd s3,120(sp)
看来此时,PC 已经进入了内核。
至此,我们用 gdb 看到了 QEMU 启动流程中的几次跳转。
文章来源:
Author:me@skywt.cn
link:https://skywt.cn/blog/rcore-tutorial-chapter-1/