IO及IO模型
IO,即Input/Output,指的是程序从外部设备或者网络读取数据到用户态内存/从用户态内存写数据到外部设备或者网络的过程。
普通的IO过程
一般的IO,其流程为,
Java进程调用read() write()系统调用函数,进入内核态;
内核中的相关程序将数据从设备缓冲区拷贝到内核缓冲区中;
把数据从内核缓冲区拷贝到进程的地址空间中去
这就完成了一次Input,Output反之。
以磁盘IO为例,一次普通IO的流程如下:
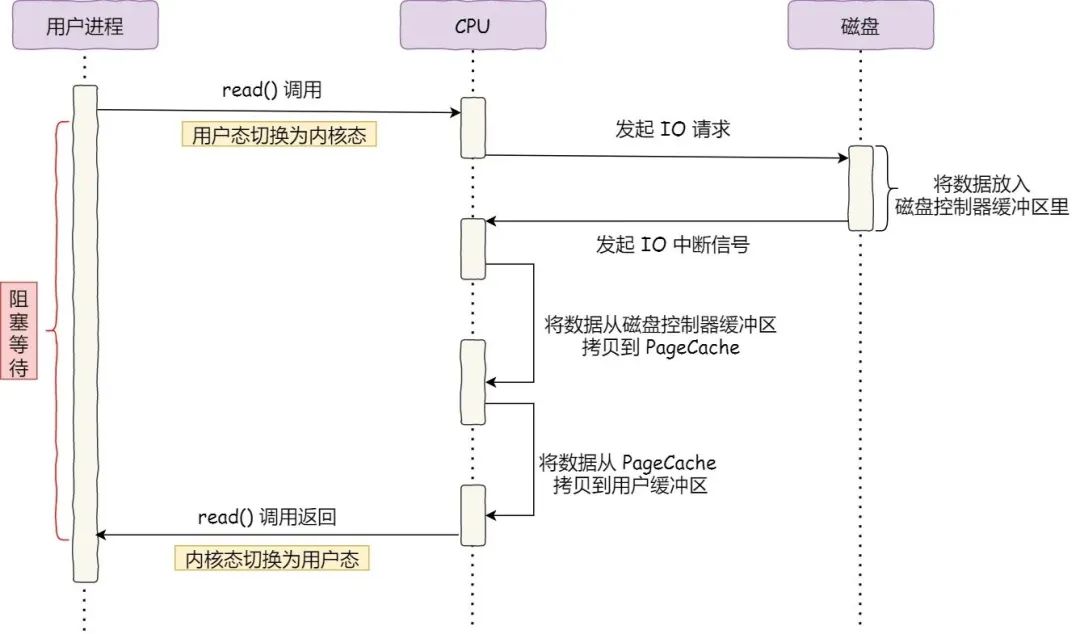
这里有两个耗时的操作,一是从设备拷贝数据到内核缓冲区(磁盘准备数据慢,这里的设备缓冲区就是磁盘控制器的缓冲区,内核缓冲区就是PageCache),二是从内核缓冲区拷贝数据到进程的用户态内存空间(涉及到内核态到用户态CPU上下文的切换)。
内核缓冲区的作用是解决第二个问题,一次性拷贝一批数据,从而避免频繁且缓慢的磁盘IO或者与其他设备的IO。
字节缓冲流诸如BufferedInputStream作用是解决第一个问题,一次性从内核缓冲区拷贝一批数据到进程的缓冲区中,这个缓冲区位于进程的地址空间,之后接着取数据,如果缓冲区中还有数据,就无需系统调用而拿到数据,避免了大量的系统调用开销。
这是普通的IO操作,除此之外还有各种方式用于加快IO,譬如DMA、零拷贝技术等。
网络IO
服务端如何实现高并发、海量连接与网络IO的方式有着千丝万缕的联系,与磁盘IO不同的是,网络IO是从网卡拿数据,仅此而已
在讨论网络IO的方式之前,我们应该先对阻塞/非阻塞、同步/异步的概念有一个比较清晰的认识:
阻塞IO与非阻塞IO
如上所述,一次IO过程中数据的流动大体可以分为两步
硬件(磁盘、网卡等)到内核缓冲区 内核缓冲区到用户态进程空间通过进程在输入数据的时候,在第一步(也就是硬件到内核缓冲区)是否发生阻塞等待,可以将网络IO分为阻塞IO和非阻塞IO
具体来说,用户态进程发起了读写请求,但是内核态数据还未准备就绪(磁盘、网卡还没准备好数据),
如果进程需要阻塞等待,直到内核数据准备好,才返回,则为阻塞IO; 如果内核立马返回,不会阻塞进程,则为非阻塞IO;同步IO与异步IO
在一次IO中数据传输的两个步骤中,但凡有一处发生了阻塞,就被称为同步IO;如果两个步骤都不阻塞,则被称为异步IO。
网络IO的方式可分为三种,分别是BIO NIO与AIO.
BIO
BIO是同步阻塞的IO,在BIO的方式下,
每个连接一个线程来处理的方式消耗大量的系统资源,因为线程会占用大概几MB内存,而我们的内存却是有限的,这样的方式注定无法处理太多的请求,这样就限制住了并发数量。
NIO
NIO是同步非阻塞IO,在NIO的方式下,相比BIO有如下优势:
NIO不需要为每个网络连接开一个线程来处理,而是使用一个线程监听多个网络连接,当有连接的数据准备就绪,则进行处理,大大减少了处理并发所需的线程数量;
NIO中,当进行IO操作时,程序可以立即返回,而不需要等待内核数据就绪,通过轮询或者监听,程序可以知道哪些连接已经准备好了数据或者可以写入数据了。针对就绪的连接执行数据处理操作,而不会阻塞某一个特定的IO上,因此称为非阻塞IO;
NIO是需要内核提供支持的,在创建了连接后,调用fcntl(sockfd, F_SETFL, flags | O_NONBLOCK)将其设置为非阻塞。
但是NIO也有较为明显的缺点:因为要轮询确定内核数据有没有就绪,这会产生大量的系统调用(每一次轮询是一次系统调用),这会大量消耗系统资源。
AIO
AIO是异步非阻塞IO,当进行读写的时候,进程只需要调用API的read或write方法,当IO结束,调用回调函数通知用户线程直接去取数据就好了,与NIO不同的是,AIO是把数据从内核拷贝到用户态也交给了系统线程去处理,整个IO过程无需用户线程参与。
IO多路复用
为了解决上面提到的NIO会导致大量系统调用的问题,出现了IO多路复用模型。
IO多路复用不是简单的一个线程管理多个网络连接,因为在未采用IO多路复用的NIO中,就可以做到一个线程管理多个网络连接(依次轮询它所管理的网络连接),那么IO多路复用的本质应该是什么呢?
IO多路复用实际上复用的是系统调用,它可以使用有限的系统调用来管理多个网络连接,具体地说,将一批网络连接丢给内核,让内核告诉我,哪几个连接的数据准备好了,这样一次系统调用就可以检查多个网络连接。
在Linux中,IO多路复用的实现主要有select poll epoll,都是采用上述思想设计的,不过它们之间又略有不同。
select
select在使用时其实是一个函数,传入我们想要监听的文件描述符,程序在调用select时会阻塞,直到有文件描述符就绪或者超时,函数返回。
select返回已经就绪的文件描述符并遍历,逐个执行IO操作。
select的缺点是单个进程可以监视的文件描述符的数量有限,在Linux上的限制是1024。
poll
poll可以看做是select的升级版本,它不限制可以监听的文件描述符的最大数量。
epoll
select和poll所共有的缺点是,用户需要每次都将海量的的文件描述符集合从用户态传递到内核态,让内核去检测哪些文件描述符就绪了。
由于频繁的大量文件描述符拷贝,这里是比较耗时的,于是就有了epoll.
在调用epoll_wait()的时候会阻塞,直到有文件描述符就绪被返回,线程遍历就绪的文件描述符,依次进行IO操作。
相比于select poll,epoll无须频繁地拷贝大量的文件描述符,因为epoll预先在内核中分配了空间,添加需要监听的文件描述符只需要传递新增的文件描述符即可,大大提高了效率。
文章来源:
Author:月梦
link:https://ymiir.netlify.app//高并发/IO原理.html