我试图用 GPT 改造 Google 统计,但最终变成了一个有点鸡肋的产品
自从几个月前我开始用 AI 改造热量记录工具,发现效果不错之后,我就开始琢磨用 AI 干点更复杂的事情,想必很多人都和我一样,对于网络上铺天盖地的AI毁灭世界论,以及实际上看到最多的例子就是用AI来生成色图和软文的现状,感到有点不满。
在这篇文章,我会讲述一个实际例子,一个试图让 AI 能力和复杂逻辑相结合,成为一个更好用的工具的例子,在这个过程中,我也发现了在面对多维复杂性时——输入的复杂和处理的复杂,即便是最顶尖的 AI 模型也难以解决的问题。
Google Analytics
我是一个Google Analytics( Google 统计)的用户,Google统计,也被称之为 GA,应该是最老牌的网站统计服务之一,网站统计服务,某种意义上,是任何网站和 app 都必须使用的服务,你只需要在代码中植入一小段,然后就能直观的看到你的网站有多少人来过,他们看了些什么,他们从哪里来等等。
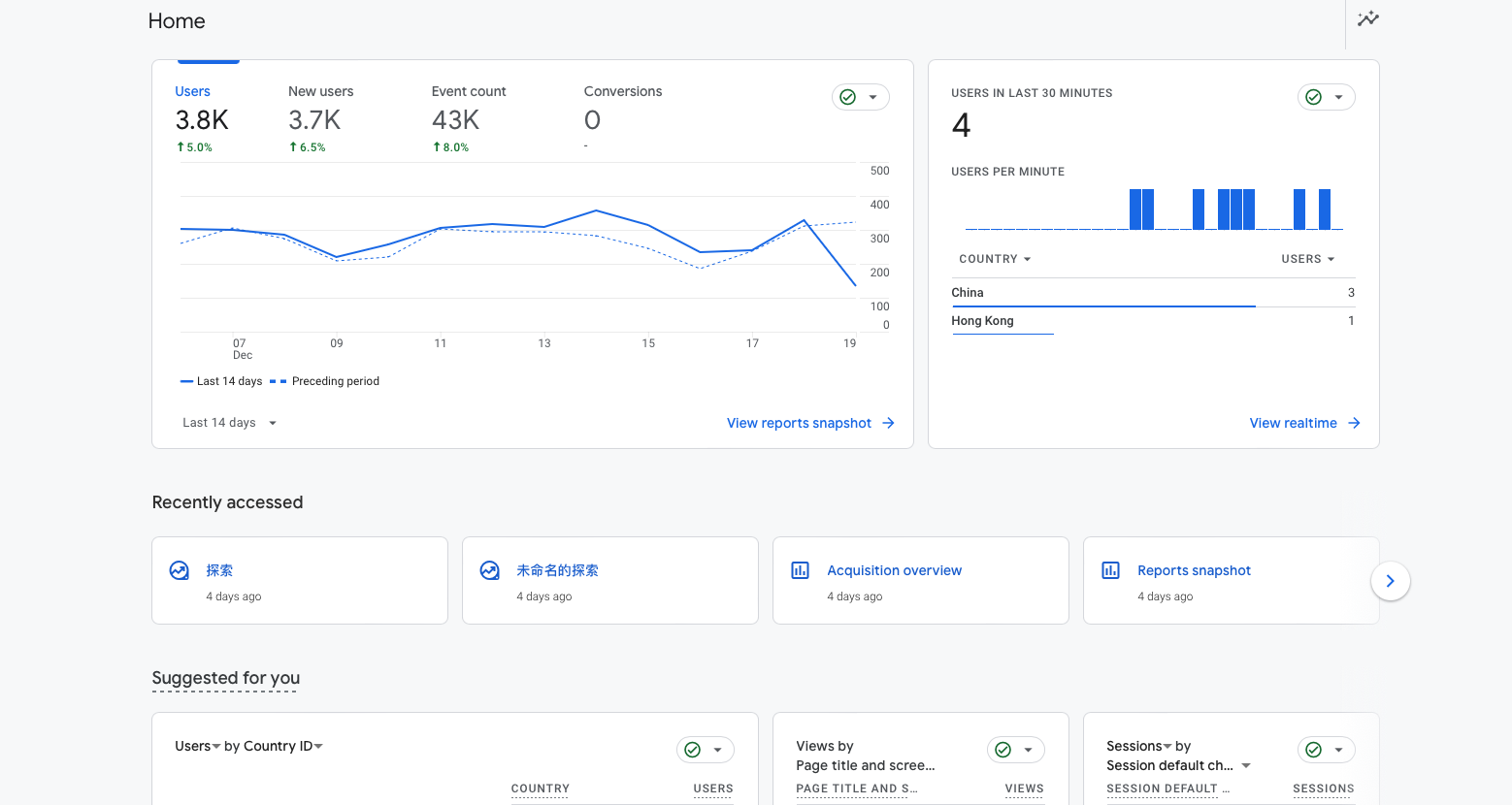
去年,Google 统计进行了改版,升级为了 GA4,这项升级前卫但复杂,很多老用户对新版 Google 统计感到茫然,因为熟悉的东西都没了,想看一些针对性的数据,需要自己创建报告,这又是一个极其复杂的页面:
搭配 GA4,Google 也一起发布了新的 API,调用这些 API,可以从GA 获得任何你想要的数据。因此,当我看到 openai 发布 functions 功能后,我开始意识到,我也许能用AI来改造 GA,让它更人性化一点。
GPT functions
我的构想非常简单,用户输入希望看到的数据,交由 gpt functions 转化为需要调用的API,然后再去 GA调用API,然后将获得的数据进行渲染。
但当我真正开始了解 gpt functions 的时候,我发现这里还差得远。
首先 gpt functions 支持的参数类型非常有限,主要是枚举和字符串,但是当我需要以数组类型传递参数,并且数组包含的值是枚举中的不确定的几个的时候,functions 就完全没办法实现。
然而让我懵逼的不是这个,而是即便我按照文档,在输入中确定了枚举的值,gpt 依然会有幻觉,捏造出一个不在枚举中的字符串。这种情况的 GPT 有点类似于下面的领导。

解决这两个问题花费了我大量时间,事实是我其实没办法「解决」,而只是「绕过」了这些问题,我根据 Google 文档,手写了大量规则来修正模型输出的错误。
在这些工作完成后,我终于可以做出一个 demo,它具备这样的能力:你直接描述你想要看到什么数据,然后就能看到,例如:
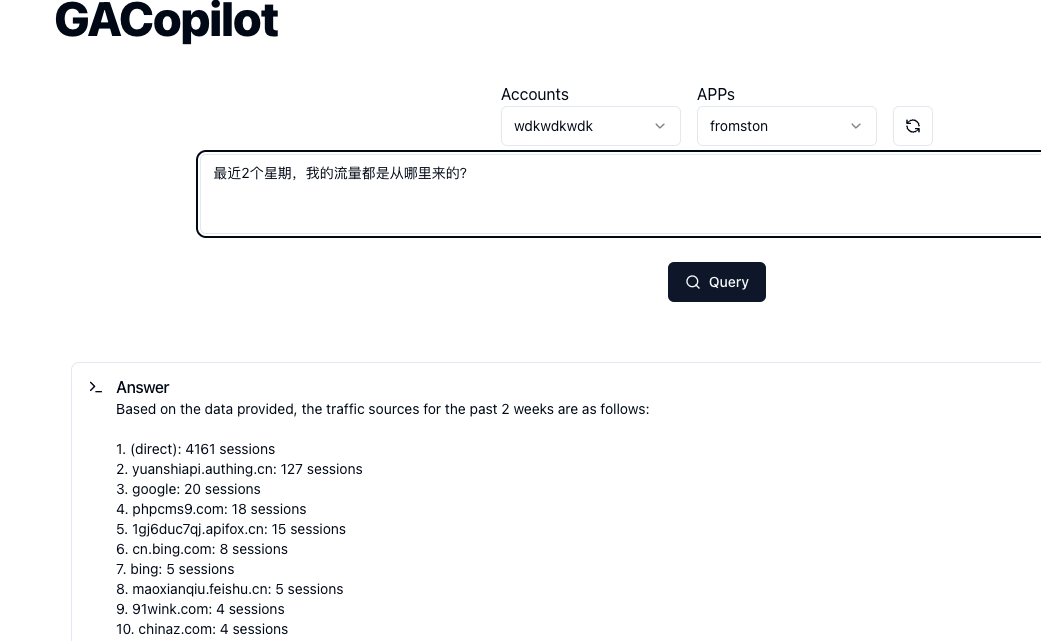
这个原型产品其实花费了我大量的精力,因为我需要把 Google的 API 全部捋一遍,在这个过程中,我发现了我面对的这些 API 的复杂之处。
GA 的核心 API,叫做 runReport,核心参数主要有两个,一个是维度(dimension),一个是指标(metric),例如,把城市设定为纬度,总用户设定为指标,那么就能获取每个城市的用户:
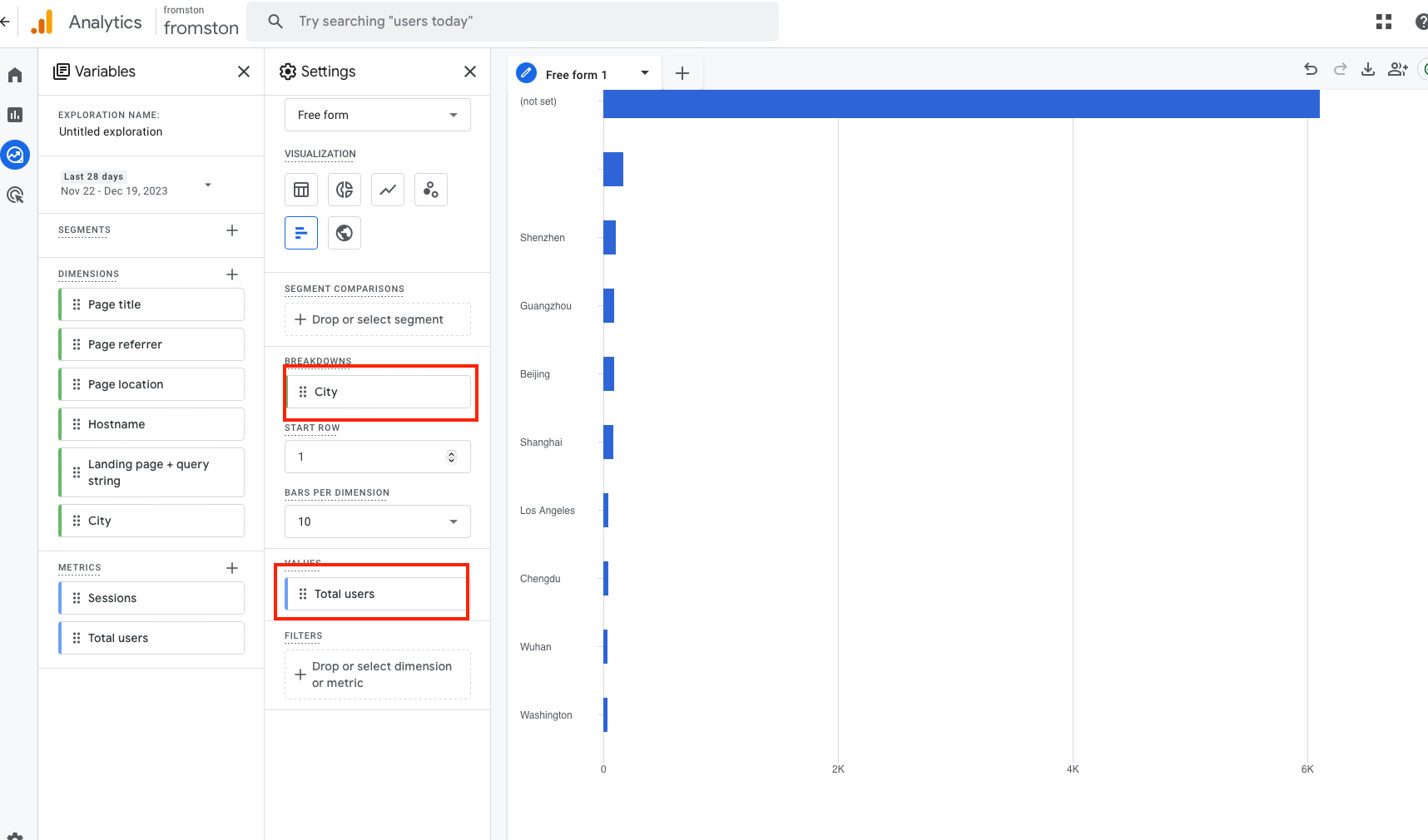
GA 支持相当多的纬度和相当多的指标(大几十种)
将这些指标和纬度告诉 gpt,并让其选择合适的,似乎行得通,但马上我们会遇到更复杂一些的情况。
复杂之处
GA 的接口,支持你传入多个纬度和多个指标,这让获得的数据变成了多维的,例如,维度设定为「城市」和「日期」,指标依然是「总用户」,那么 GA 会将每个城市和每天的总用户都输出,当我需要知道北京11月21日有多少用户访问时,合理的设置多个纬度就可以达到这个目的。
但这只是第一层的复杂度,即多维度,多指标。
GA 同时支持一个叫做「筛选」的参数,这个筛选参数非常复杂,也非常强大,它支持纬度的筛选和指标的筛选,并且每个筛选都支持多种控制逻辑:和/与/非
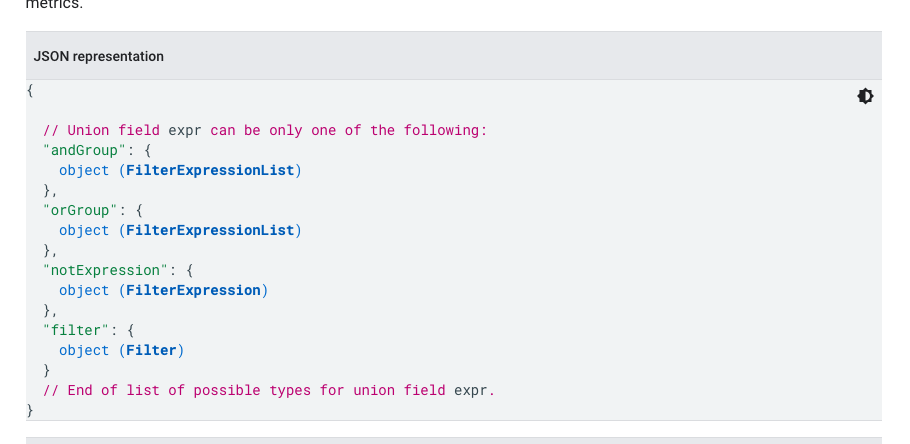
而在和/与/非逻辑之中,还可以设定匹配类型和匹配逻辑,甚至可以写正则。

同样在上面的例子中,如果我想知道「北京11月21日有多少用户访问」,除了设定多个纬度之外,更简单的办法则是设置单一维度「日期」,但是将筛选项设定为「城市包含北京」
这是第二层复杂度,即筛选逻辑的控制。
然而,GA 还有一个接口,即 batchRunReports,同时获取多个数据报告,每个报告都包含独立的纬度,指标和筛选,并汇总给你,在面对相当复杂的需求时,往往需要汇总多个报告的数据才能达到目的,而这是第三层复杂度。
在梳理 API 的同时,我也在对 GPT 能力进行实验,我发现即便还不涉及到第一种复杂度,gpt functions已经错误频出,而当我要求其设置多个纬度和参数时,给出的结果更是糟糕——我用的是GPT4,这应该是目前最智慧的大模型。
GPT 似乎只能处理最简单的情况,例如「过去一周的活跃用户」或「最受欢迎的页面有哪些」,这些情况仅下,需要一个纬度和一个指标就能获得合适的数据,但如果我的需求描述的再复杂一点,例如「来自北京的用户最喜欢浏览什么页面」,那么极大概率 GPT 就无法给出正确的参数。
讲道理,如果因为上面的问题,认为 GPT 很愚蠢,那就很愚蠢了,因为我给 GPT 的任务,其实是复杂的数据分析任务,这里面需要:
1.判断用户的问题和需求
2.筛选可能适合的字段和接口使用方式
3.合理的使用这些字段,得到精确的调用参数
这些需求并不简单,能够从 GA 中手动获取到「来自北京的用户最喜欢浏览什么页面」,并且进一步给出一些建议和结论的人,理论上已经可以胜任初级的数据分析师了,拿几千块钱一个月应该问题不大。
可能的办法
事实上,确实可以通过一些办法来提高效果,例如,用 agent 思维,将一个查询拆分成多个数据获取任务,然后每个任务都通过GPT 函数给出接口运行的参数,然后再进行汇总。
但这个过程过于复杂,而且很难进行完全的工程化,还会造成成本直接提高数倍,所以目前还很难运用到项目上。
另一种方案是将 gpt 进行微调,喂入 GA API 文档的相关数据,理论上这应该可以让模型对接口更熟悉,也会更容易给出合理的参数,但是这一步成本则更加高昂,并且 GPT4 还没有微调的接口开放,所以我没有测试。
正因为如此,这个项目我撸了一周之后,发现它变得有点鸡肋:它确实实现了将口语表达的查询,转化成直接的数据图表和结论,但当你的需求比较复杂的时候,它则会失效,而后者,才是我开始希望做这个产品的原因。
目前这个产品我已经发布到线上了,虽然我设置了付费计划,但我不认为真的会有人愿意为之付费,因为就目前的能力来说,它能获取的数据只有最浅表的一层,能够给出的结论和分析也浮于表面,如果你感兴趣,可以直接去试试看(GACopilot)。
但另一方面,我毫不怀疑,随着模型能力的提高,或者一些新的模型工具和使用思维的诞生,这一工具可以变得更有用,我也确信,当下的这些问题并非能够通过 prompt 工程来解决,也正因为如此,这才是一个更有价值的 AI 能力的应用方向。
这是我的一点探索,大模型事实上已经进入我们的日常生活了,但我认为还只是一个非常早期的开始,与我们息息相关的越来越多的东西都会融入大模型的能力,但很明显,离 AGI 或者能毁灭人类,还有相当遥远的时间。
文章来源:
Author:DK
link:https://greatdk.com/1958.html