觅迹寻踪之正则表达式

觅迹寻踪之正则表达式
4月28日灵魂拷问
成功骗你点进来,准备好学习新知识了吗?“应该是没有”
不知道你有没有听过,正则匹配。它的使用场景是什么?“在多个文本中,找到 【我最帅】”
这篇是原理篇,可能有点晦涩。
背景
把 正则表达式 理解为一门编程语言,那它可能会有 解析引擎 和 执行引擎。
希望通过介绍正则表达式的执行引擎,了解其实现原理,能帮助大家写出更优雅的正则表达式。

执行引擎
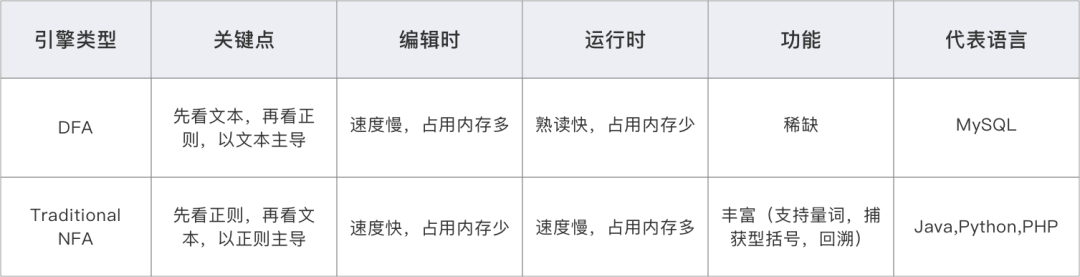
正则表达式的执行引擎主要分为两个大类:DFA (Deterministic finite automaton) 确定型有穷自动机
NFA (Non-deterministic finite automaton) 非确定型有穷自动机
其中:1. NFA 中可以再进行细分,分为 POSIX NFA 和 Traditional NFA
2. 还有些程序支持 DFA 和 NFA 混合体 整理为表格如下:
 > 章节原因,FA,DFA,NFA 之间的关系,留待下一次叙述
> 章节原因,FA,DFA,NFA 之间的关系,留待下一次叙述
DFA 执行引擎
 由上可以得出,
由上可以得出,DFA 的特点:
1.先看文本,再看正则,以文本主导
2.编译完表达式后,还需要遍历出表达式中所有的可能
3.匹配过程,字符串只看一次
NFA 执行引擎
> 文中的NFA ,指的都是 Traditional NFA

NFA 的特点:
1.先看正则,再看文本,以正则主导
2.编译完表达式即完成
3.匹配过程中,可能会发生回退,字符串同一部分会比较多次 (通常将回退称为回溯)敲重点

如何区分
如何区分Traditional NFA, POSIX NFA, DFA, DFA/NFA
第一步:
看是否支持 忽略优先量词。如果支持,基本就能确定是 Traditional NFA
正则表达式 nfa|nfa.not,文本 nfa.not
nfa ,基本就能确定是 Traditional NFA
第二步:
看是否支持 捕获型括号 或者 回溯。如果支持,基本能确定是 POSIX NFA
正则表达式 X(.+)+X,文本 XxX==============
如果出现灾难性回溯,基本能确定是 POSIX NFA
DFA 和 NFA 两种引擎的混合的工具
细品 NFA 回溯
上文提到,NFA 具有回溯的能力,该能力是一把双刃剑
因为回溯会增加匹配的步骤,步骤过量会导致 CPU 使用率飙升
正所谓
 因此了解回溯出现的场景十分有必要
因此了解回溯出现的场景十分有必要
常见场景
贪婪模式
过程 关键点
1.贪婪,每次都尽可能多标绿匹配的内容。
关键点
1.贪婪,每次都尽可能多标绿匹配的内容。

2.回溯。当正则需要匹配下一个文本内容时候,发现不匹配,文本只能回退一步。

惰性模式
过程 关键点
1.懒惰,每次尽可能少标绿匹配的内容。
关键点
1.懒惰,每次尽可能少标绿匹配的内容。
 2.回溯。当正则需要匹配下一个文本内容时候,发现不匹配,文本只能回退一步。
2.回溯。当正则需要匹配下一个文本内容时候,发现不匹配,文本只能回退一步。

分组模式
过程 关键点
1.分组,按照分支的顺序逐个匹配。
关键点
1.分组,按照分支的顺序逐个匹配。
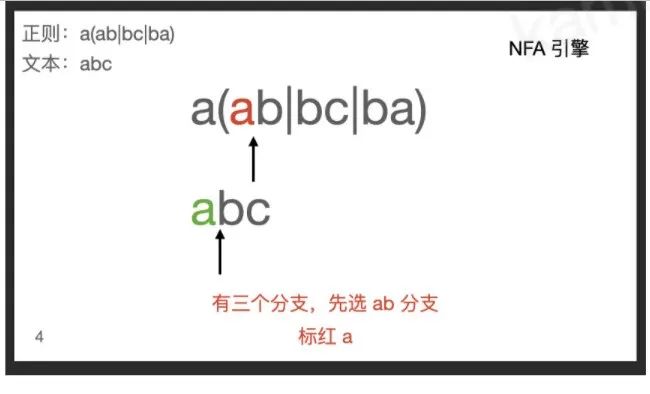 2.回溯。当正则需要匹配下一个文本内容时候,发现不匹配,文本只能回退一步。
2.回溯。当正则需要匹配下一个文本内容时候,发现不匹配,文本只能回退一步。
 > 关于什么是贪婪模式,懒惰模式,独占模式,分组模式 不在这里展开详细叙述,留待下一次讲解
> 关于什么是贪婪模式,懒惰模式,独占模式,分组模式 不在这里展开详细叙述,留待下一次讲解
实(踩)战(坑)例子
检验 商店名字 地址是否合法
背景 检验 商店名字 地址是否合法,规则:1.英文字母大小写 2.数字 3. 越南文 4.一些特殊字符,如
&,-,_ 等使用以下正则作示例:
^([A-Za-z0-9._()&'\- ]|[aAàÀảẢãÃáÁạẠăĂằẰẳẲẵẴắẮặẶâÂầẦẩẨẫẪấẤậẬbBcCdDđĐeEèÈẻẺẽẼéÉẹẸêÊềỀểỂễỄếẾệỆfFgGhHiIìÌỉỈĩĨíÍịỊjJkKlLmMnNoOòÒỏỎõÕóÓọỌôÔồỒổỔỗỖốỐộỘơƠờỜởỞỡỠớỚợỢpPqQrRsStTuUùÙủỦũŨúÚụỤưƯừỪửỬữỮứỨựỰvVwWxXyYỳỲỷỶỹỸýÝỵỴzZ])+$
调试
我们使用正则验证工具(regex101)进行调试
1.文本:this is good
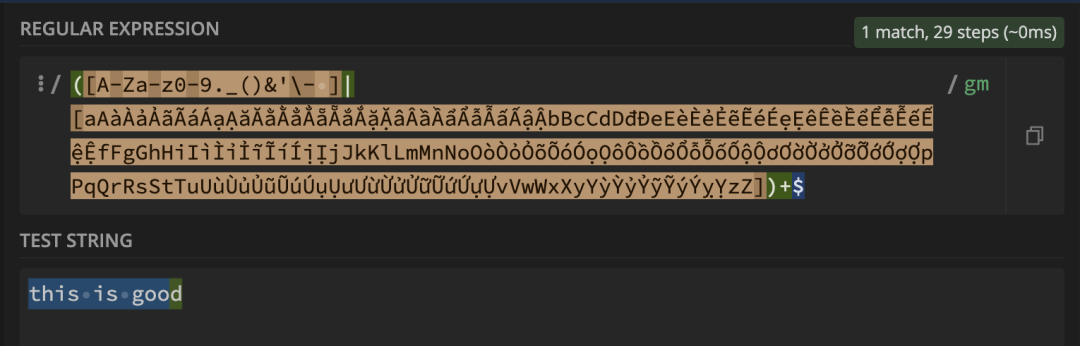 2.文本:
2.文本:this is good,
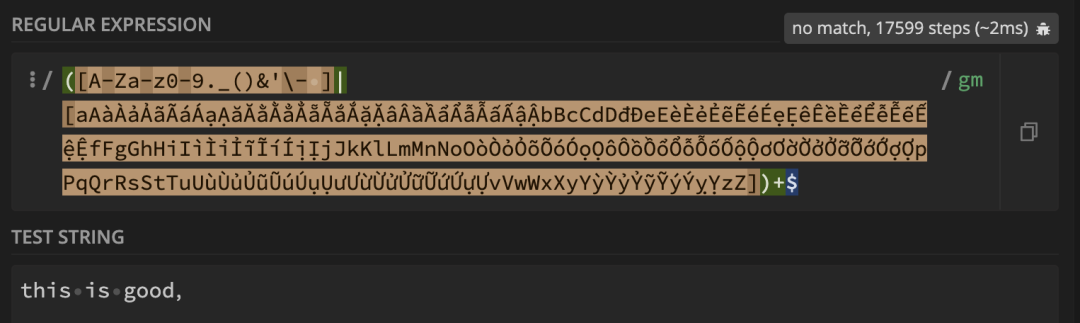 发现输入
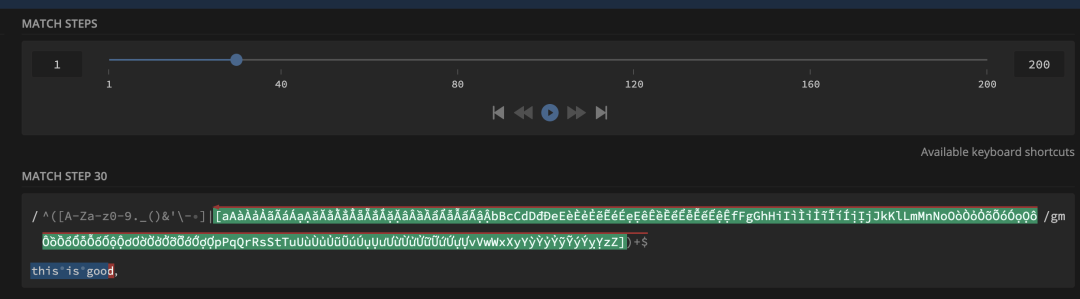
发现输入 this is good, 竟然要多达 17599 步才完成匹配
 3.抽丝剥茧
上述的正则表达式看上去写得很复杂,实际可以简化一下:
3.抽丝剥茧
上述的正则表达式看上去写得很复杂,实际可以简化一下:
^([符合要求的组成1]|[符合要求的组成2])+$
能发现正则表达式中有 + 出现,意味着有贪婪匹配,可能会有大量回溯
利用 regex101 工具中的调试功能,发现当到 30+ 步数,就开始进行回溯
 我们尝试将贪婪模式改成独占模式,即修改为:
我们尝试将贪婪模式改成独占模式,即修改为:
^([A-Za-z0-9._()&'\- ]|[aAàÀảẢãÃáÁạẠăĂằẰẳẲẵẴắẮặẶâÂầẦẩẨẫẪấẤậẬbBcCdDđĐeEèÈẻẺẽẼéÉẹẸêÊềỀểỂễỄếẾệỆfFgGhHiIìÌỉỈĩĨíÍịỊjJkKlLmMnNoOòÒỏỎõÕóÓọỌôÔồỒổỔỗỖốỐộỘơƠờỜởỞỡỠớỚợỢpPqQrRsStTuUùÙủỦũŨúÚụỤưƯừỪửỬữỮứỨựỰvVwWxXyYỳỲỷỶỹỸýÝỵỴzZ])++$
再尝试:
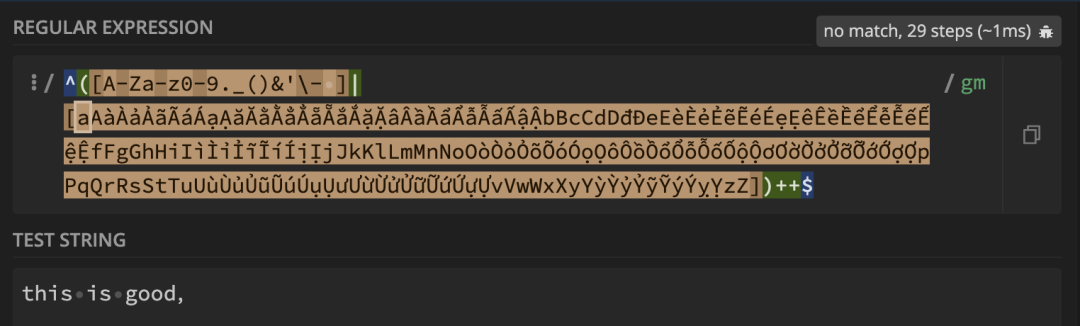 改为独占模式后,匹配步数锐减到 29 步
改为独占模式后,匹配步数锐减到 29 步
> 使用独占模式,需要注意两点:1. 是否满足业务需求;2. 使用的编程语言是否支持
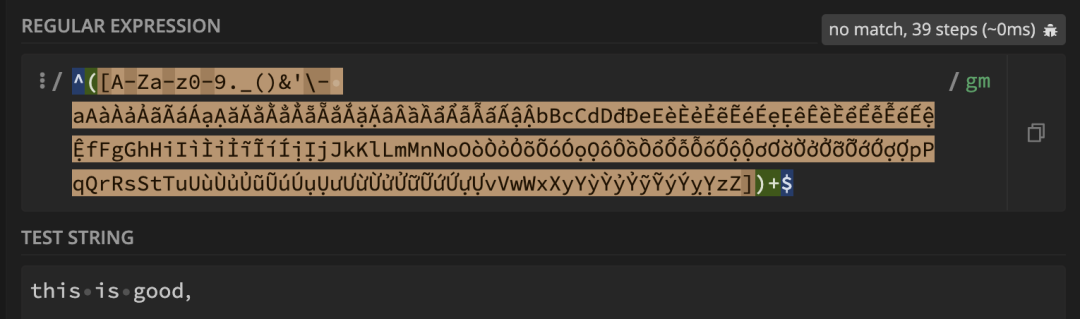
再优化 正则表达千万条,还有其他优化的方案 在原有^([A-Za-z0-9._()&'\- ]|[aAàÀảẢãÃáÁạẠăĂằẰẳẲẵẴắẮặẶâÂầẦẩẨẫẪấẤậẬbBcCdDđĐeEèÈẻẺẽẼéÉẹẸêÊềỀểỂễỄếẾệỆfFgGhHiIìÌỉỈĩĨíÍịỊjJkKlLmMnNoOòÒỏỎõÕóÓọỌôÔồỒổỔỗỖốỐộỘơƠờỜởỞỡỠớỚợỢpPqQrRsStTuUùÙủỦũŨúÚụỤưƯừỪửỬữỮứỨựỰvVwWxXyYỳỲỷỶỹỸýÝỵỴzZ])+$ 基础上优化
移除重复的字母(不要在多选择分支中,出现重复的元素)
^([0-9._()&'\- ]|[aAàÀảẢãÃáÁạẠăĂằẰẳẲẵẴắẮặẶâÂầẦẩẨẫẪấẤậẬbBcCdDđĐeEèÈẻẺẽẼéÉẹẸêÊềỀểỂễỄếẾệỆfFgGhHiIìÌỉỈĩĨíÍịỊjJkKlLmMnNoOòÒỏỎõÕóÓọỌôÔồỒổỔỗỖốỐộỘơƠờỜởỞỡỠớỚợỢpPqQrRsStTuUùÙủỦũŨúÚụỤưƯừỪửỬữỮứỨựỰvVwWxXyYỳỲỷỶỹỸýÝỵỴzZ])+$
移除多选分支选择结构(直接用中括号表示多选一)
^([A-Za-z0-9._()&'\- aAàÀảẢãÃáÁạẠăĂằẰẳẲẵẴắẮặẶâÂầẦẩẨẫẪấẤậẬbBcCdDđĐeEèÈẻẺẽẼéÉẹẸêÊềỀểỂễỄếẾệỆfFgGhHiIìÌỉỈĩĨíÍịỊjJkKlLmMnNoOòÒỏỎõÕóÓọỌôÔồỒổỔỗỖốỐộỘơƠờỜởỞỡỠớỚợỢpPqQrRsStTuUùÙủỦũŨúÚụỤưƯừỪửỬữỮứỨựỰvVwWxXyYỳỲỷỶỹỸýÝỵỴzZ])+$
检验 URL 地址是否合法
背景检验 URL 地址是否合法,规则如下:
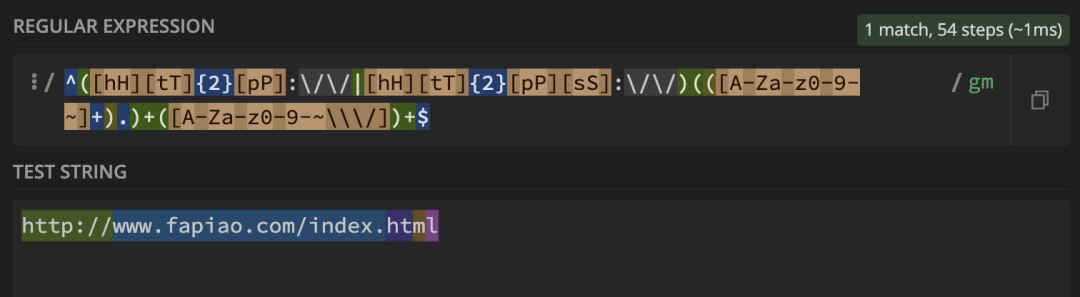
^([hH][tT]{2}[pP]:\/\/|[hH][tT]{2}[pP][sS]:\/\/)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~\\\/])+$
调试
1.文本:
http://www.fapiao.com/index.html
2.文本:
http://www.fapiao.com/dzfp-web/pdf/download?request=6e7JGm38jfjghVrv4ILd-kEn64HcUX4qL4a4qJ4-CHLmqVnenXC692m74H5oxkjgdsYazxcUmfcOH2fAfY1Vw__%5EDadIfJgiEf
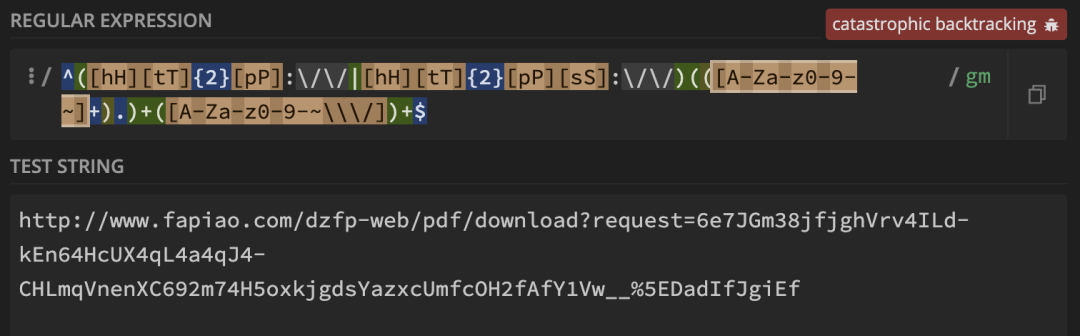 发现输入案例后出现
发现输入案例后出现 catastrophic backgracking (灾难性回溯),

重新梳理一下正则表达:
1.校验协议:^([hH][tT]{2}[pP]://|[hH][tT]{2}[pP][sS]://)
2.校验域名:(([A-Za-z0-9-~]+).)+
3.校验参数:([A-Za-z0-9-~\\/])+$
看出来,是因为用户传入的内容中存在_% ,那我们修改一下[校验参数]部分,把 _% 加上:
^([hH][tT]{2}[pP]:\/\/|[hH][tT]{2}[pP][sS]:\/\/)(([A-Za-z0-9-~]+).)+([A-Za-z0-9-~_%\\\/])+$
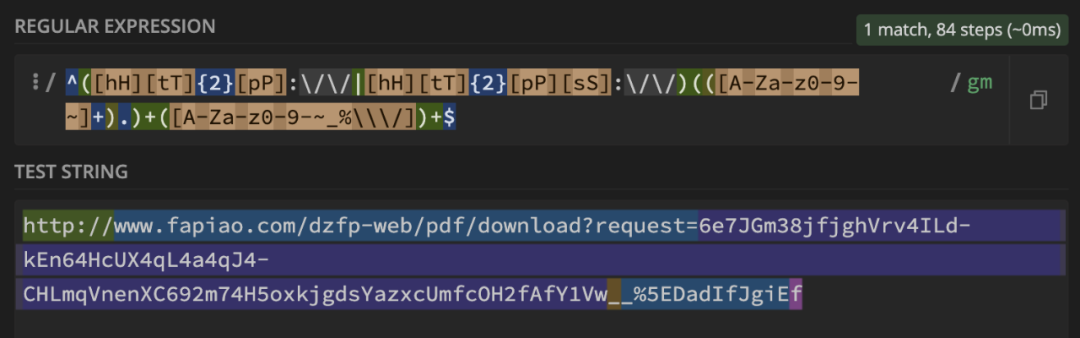
从 catastrophic backgracking 变成 84 步 完成
但问题来了,如果用户在文本中加上 , 呢?

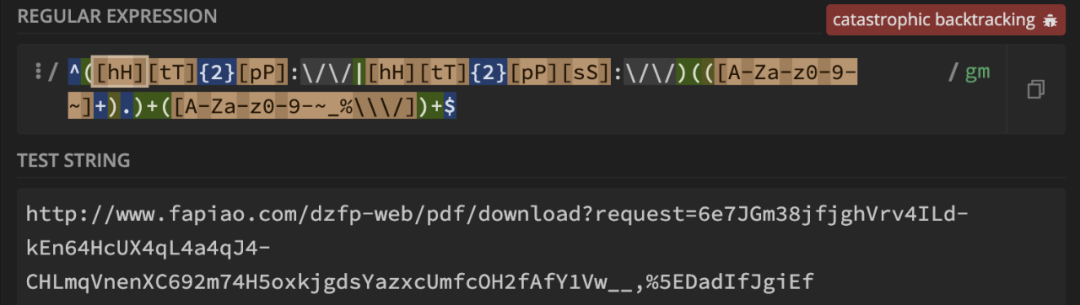 刚刚的修改仅仅是优化了参数中可能会出现
刚刚的修改仅仅是优化了参数中可能会出现 _% 的情况
要想彻底解决问题,可以尝试一下使用独占模式,那需要修改哪部分呢?
利用 regex101 工具中的调试功能,能发现当到 60+ 步数,就开始进行回溯
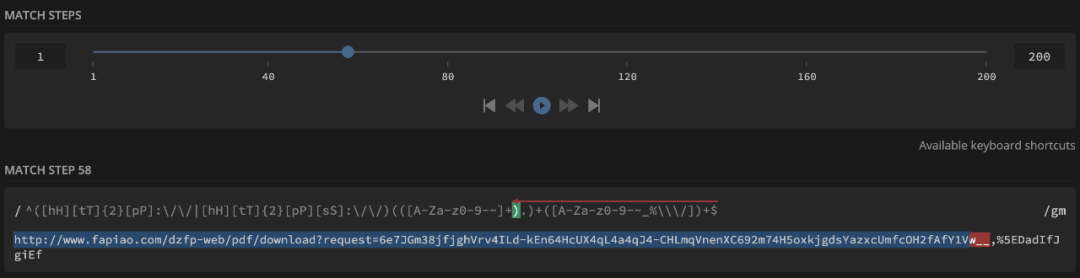 我们可以尝试将[校验域名]修改为独占模式,即修改为:
我们可以尝试将[校验域名]修改为独占模式,即修改为:
^([hH][tT]{2}[pP]:\/\/|[hH][tT]{2}[pP][sS]:\/\/)(([A-Za-z0-9-~]+).)++([A-Za-z0-9-~\\\/])+$
再尝试:
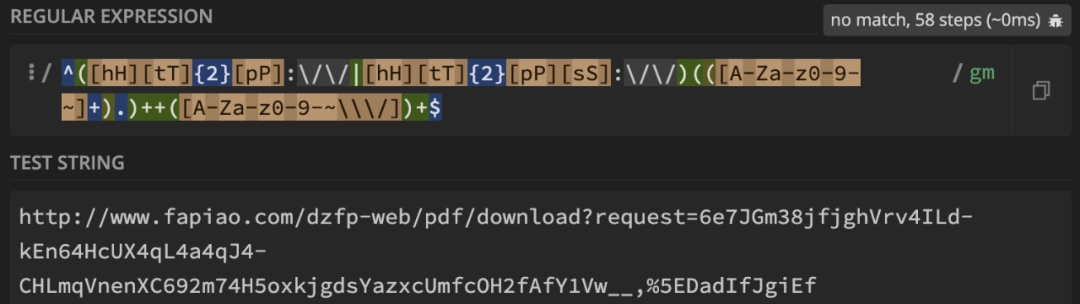 改为独占模式后,匹配步数也锐减到 58 步
改为独占模式后,匹配步数也锐减到 58 步
课代表
从上面案例可知,避免回溯地狱
1.在满足需求情况下,尝试使用独占模式 -> 案例 1,2 可知
2.移除重复的字母(不要在多选择分支中,出现重复的元素) -> 案例 1 可知
3.移除多选分支选择结构(直接用中括号表示多选一)-> 案例 1 可知 本章节不过多介绍,优化内容,期待下次透析….参考资料
如何理解正则的匹配原理以及优化原则?
把握开发利器 — 正则表达式
正则表达式引擎执行原理——从未如此清晰!- SegmentFault 思否
正则表达式里的底层原理是什么
一个由正则表达式引发的血案

文章来源:
Author:CDCer
link:https://cdc.tencent.com/2021/06/22/觅迹寻踪之正则表达式/