前端状态管理设计——优雅与妥协的艺术
如果我仍然去解释什么是状态管理器,为什么我们需要它,这篇文章将会索然无味。我的想法是,我们原本不需要状态管理器,但我们确实需要状态管理。
前端状态管理
非要去深究“状态”这个词,从后端服务的角度去解释更加能让我们理解。一言概之,我自以为是地总结,“状态”的意思就是:现在的样子。一个服务现在的样子主要是由运行时所产生的内存和运算决定的,而且,它有终极的时间观念,理论上任何时刻的状态都不同,因为它内部必然会有即使细微的变化。
前端状态管理这个概念出现之前,就已经有状态管理的实践了。我在2010年开始使用jquery,这是一个非常了不起的库,它将复杂的DOM操作,通过简化和封装,成为实质上的行业标准。HTML5标准发布后,采用了querySelector这个接口,可以说它完全是基于开发者对jquery的认可度的考虑。那这和状态管理有什么关系呢?我想说的是,在jquery的年代,虽然“前端状态管理”这个概念还没有产生,但是状态管理确真实存在。我们用一段基于jquery的伪代码来看看。

我们在实践中,使用dataset的特性,直接在被操作的DOM节点上对一个模态框的隐现状态进行管理。而在其他地方,我们可能会读出这个状态值,用来判断是否要执行某些操作。
你看到的这种操作,在我们将“前端状态管理”的概念抽象化之前,几乎随处可见。当然,这是一种原始的状态管理,它只能处理单一的、分散的、临时的状态,无法对复杂的、耦合(依赖)的、持久的状态进行深度处理,或者说处理起来很麻烦。其中的典型案例就是我多次提及的表单业务,在一个表单业务中使用jquery进行开发,所有的表单数据,必须分散的、随意的,提交的时候,必须从很多个地方把这些数据找出来,甚至还比较难找。
我们不禁要问:状态管理的本质是什么?起码,在这一阶段,我们已经知道一个事实:
# 某一状态能够被有效记录。
我大学本科和硕士所属专业的大类学科是管理学,不同专业对管理的解释不同,而对我而言,记录则是一种有效管理。就像jquery时代,我们找到一种虽然原始,但行得通的方式管理状态。
但是,我们往往发现,我们正在实践的东西,有些是非常优秀的,但是,必须等到很多年(3-5年)之后,被其他团队的某个项目带热之后,才证明我们正在实践的东西是对的,是走在趋势上的,然而我们没有坚持到最后,因为最后我们采用了市面上最热门的框架或库。超前的东西往往一开始有很多人同时实践,但是随着时间流逝,这些实践的人中,很多退出了,在沉寂的发展中,会有一些坚持下来的团队,最终成为主流,比如angularjs团队。但不要着急,在angularjs还默默无闻时,甚至已经初露端倪时,仍然还是jquery的天下,直接对DOM节点操作的前端编程范式持续了至少6年,直到react提出virtual dom这样先进的理念之后,jquery才逐渐淡出历史舞台。angularjs团队至始至终都没有超出jquery的统治高度。
没有超出jquery统治高度的,还有backbone。我也多次提到过这个库,它至今还活着,你可以通过这里查看它的文档。backbone的成就核心在于它的Model(backbone是一个真正意义上的前端框架,但是它不处理view部分,它提供了view的编程范式,但你需要使用jquery来完成所有view的更新)。我们来看一个例子吧。
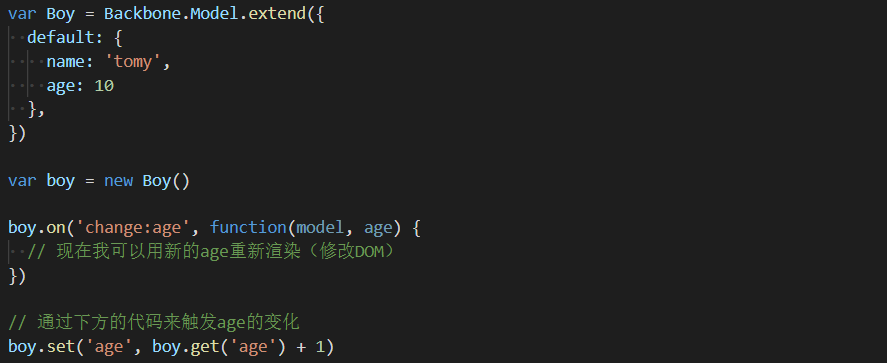
backbone中可没有我们现在熟知各种花里胡哨的操作方式,对于模型实例中的状态,只能通过get进行获取,通过set进行修改,set也支持传入对象批量修改。而它最大的亮点,在于模型上的on方法,这个方法实现了状态管理的一个质变。
# 状态的变化能被有效感知和响应。
on/off这对监听方法来源于jquery,但超越了jquery。jquery中只针对DOM的事件系统,而backbone可以脱离DOM,对数据变化进行监听。当数据的变化被监听之后,就可以在监听函数中对view进行修改,而对于事件的响应,只需要调用set方法修改数据。这样就做到了数据和界面代码的分离解耦,是一大进步。但backbone也止步于此。
使用set/get这种接口方法显然是一种妥协,而且不符合习惯的还有必须加一个change:前缀,以和普通事件区分。如果回到2018年去重新设计backbone,get可以做依赖收集,监听可以被优化,即使仍然采用set/get接口,而不采用defineProperty这样的黑魔法,也可以再进一步,然而,时代终将止步于该止步之处。
对于开发者而言,虽然可以通过对状态变化的监听,来实现状态和界面代码分离,却最终只能通过set/get这样的方法接口进行数据操作,有违编程的优雅。在这条路上,angularjs走的更远。同样是基于jquery打下的江山,backbone也是框架,angularjs也是框架,然而当我们如今回头去看,虽然angularjs也没有爆红,却踏踏实实的,成为一代框架典范,成为前端工程化之鼻祖,同时,也是前端状态管理的一大遗憾。
如果你使用过angularjs,你会喜欢上它,当然前提是在那个年代。它通过一套被称为脏检查机制的响应系统,让开发者可以通过直接修改状态属性值,就可以改变界面。我们来看下代码。

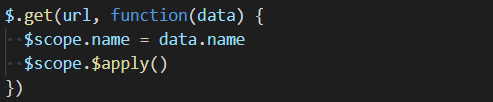
$scope 是angularjs的内置服务,为了避免一些作用域问题,推荐使用controllerAs来管理。但我们且不去讨论这些问题,我们看angularjs的代码,已然见到来当代所熟悉的编程风格了。我们可以把$scope当作是一个状态的容器,状态变化,会通过angularjs的响应系统,反馈到界面上去,view中所使用的数据素材,和$scope上的属性名完全对应。
# 状态的改变能驱动界面的变化。
angularjs的实现原理是,在ng-click的触发之后,除了调用执行$scope.updateName之外,实际上还要执行内部的digest循环过程,也就是脏检查的内部实现。只有经历完这个digest之后,才能更新视图界面。那么问题就由此而生,在有些情况下,这个digest确实没有被触发,举个例子,在原生的ajax请求结束时修改$scope.name就无法触发,于是angularjs提供了$apply方法解决这个问题。
不过,一个angularjs的应用,它的controller逐渐膨胀,慢慢的随着业务逻辑的增长,一个function被撑到上千行代码也有可能。而在这上千行代码中,要找到一个状态以及这个状态的变化过程,犹如在大海中寻找绣花针般,无计可施。
问题出在哪里呢?直到今天,angular已经迭代,旧版本几乎已经停止维护,这个问题仍然没有被回答。我个人猜测,最本质的根源在于,angularjs没有按照严格的MVC进行设计,它缺失了M层,所有的编程逻辑被写在controller函数中,任由开发者自由发挥,修改状态来驱动视图更新。由于没有对Model层进行强约束,导致代码里根本分不清哪些是用于控制视图变化的交互逻辑,哪些是用于控制数据变化的业务逻辑。而这个问题,在后来的react、vue中其实也存在。
一个更严重的问题,angularjs的directive(相当于组件)支持双向数据绑定,导致外层状态在内层directive中被修改,在调试问题时,由于无法掌握状态变化的顺序,使开发者可以崩溃到砸电脑状态。并且随着W3C标准的推进,“组件”这个概念开始慢慢成为开发的核心概念。而于此同时,同样基于组件思想而生的react就像横空出世一样,像一记银弹击碎了jquery多年美梦,从此前端编程范式实现了转变。
react的编程范式核心来自virtual dom,虚拟DOM的思想直接使得前端编程范式发生转变。通过将DOM树映射到一个内存对象,通过对虚拟DOM的对比,只更新实际DOM中的少量节点,从而避免频繁操作DOM带来的性能损耗。但virtual dom的杀手锏在于,将实际的DOM抽象为虚拟DOM之后,虚拟DOM是否再回到实际DOM就是可选择的事情,因为基于这套理论,虚拟DOM还可以为其他渲染方式提供驱动力,比如react-native,或者渲染canvas。而驱动virtual dom发生变化的,竟然是状态。这是一个颠覆性的质变。
react一直提倡一种纯UI组件,这种组件完全受控于其接收的props的值,像纯函数一样,props在解构全等的情况下,其渲染出来的效果是一模一样。而支配props变化的,来自于顶层组件一层一层的传递。最终,一个界面将要展示成什么样子,取决于一个状态,由这个状态参与组成虚拟DOM,并反映到真实DOM中去。状态发生变化时,按照一层一层传递的单向数据流方式,让所有的自组件按照最顶层组件的状态进行渲染。
# 界面是状态的映射。
在这种思想熏陶下,大约2016年,整个前端的编程范式都以此为基础,所涌现出来的vue,也直接借鉴这套思想进行编程。一个状态,对应一个界面,这简直是天才的想法。基于这种思想,把所有的状态按照时间线录制下来,就可以重放界面变化的所有,这种录制,将原本庞大的界面数据,抽象为状态这一小量数据,这种思维在游戏录制领域也被使用过。
诚然,虽然“映射”思想颠覆了传统前端编程更新DOM的范式,但react的编程范式所遵循的单向数据流却带来了巨大麻烦。这种一层一层传递的方式,虽然保证了“映射”行为的纯正性,但无法适应实际生产过程中所带来的coding和debug麻烦的问题。如果由于一个点击操作需要通过10层组件的传递,才能对点击做出响应,那么很可能就会出问题。单向数据流听起来让数据流很清晰,但是对应到代码中,发生一个事件发生后,这个事件信息,被如何传递,成为极其复杂的代码逻辑,那么看似明晰的清流,就变成了汹涌的浊流。
中心化的状态管理孕育而生,redux、mobx这些都是佼佼者。这些,就是我们当代真正意义上所称的状态管理器。它们当然是为了管理状态。redux是一朵奇葩,它火,火到爆炸,但是你去阅读它的源码,却又很简单。大道至简,在这些年的编程体验中,我逐渐体会到,简单,是一切的根本。redux的使用非常简单,接口就那么几个。然而,它却衍生出了自己的生态,它把自己的概念体系发展成为蓬勃的森林。我的天!原本简单的东西,非要通过概念复杂化。设计,核心是简单,工具,用完即走就行。同样的错误,mobx重蹈覆辙。它的设计理念也非常的具有颠覆性,引入观察者模式,将状态的变化通过观察者模式进行抽象,并且通过完美的封装,使得更新状态的方式和普通修改一个对象没有两样。然而,过渡设计让开发者望而却步。不过话说回来,在状态管理这个点上,它们的核心思想保持了一致,都是:
# 集中管理状态,共享状态。
集中管理实际上是共享的前提,但也超越了共享这一单项功能,集中管理状态,可以用一个状态,概括一组组件,甚至一个应用的整体状态。在映射思维驱动之下,连路由也要状态化,也就是说,整个应用的一切行为都由中心化的状态管理器决定。框架层、UI层只是应用的壳,而状态以及状态的驱动才是应用的魂。状态管理器,通过连接器将状态的变化反馈到具体的某个组件中,而这个组件,可以通过原本的单向数据流将状态传入更深的子组件中。UI层像提线木偶一样,被状态管理器完完全全的控制着。
然而,物极必反。react官方提出来的flux,本身就打破了单向数据流的体系,它使数据可以通过多条管道进行传递,而它的核心,就是要建立一条便捷通道,跨过多层组件,使分散在两个树枝上的节点组件直接通信。虽然flux通过非常复杂的概念,试图解释自己是遵循单向数据流,但是不可否认,它只是在原来的单向流之外,又开了一条流,现在有两条通道,但你只能选择其中之一,这样你才能单向数据流,从而保证界面和状态之间的映射关系。而且,基于context的技术是react官方给出的,flux是妥协的产物,它是为了解决react带来的问题而产生的,而很不幸,为了解决这个问题,flux带来了更多的问题,妥协,本质上是债务。
更致命的是,中心化的状态管理面临严重的问题。状态,本身是必要的。状态解决了临时保持和最终决定两个环节的冲突,以HTML中的select标签(本质就是一个组件)为例子,哪一个option被选中了呢?这得看当前select的状态,但这并不代表当前被选中的值将作为你最终提交的值,你提交的值,往往是看不见的option的value属性值。同样的情况比比皆是,例如你需要打开一个模态框,在里面输入东西,或者选择选项,但是模态框会给你一个cancel的能力,当你点击cancel的时候,之前的操作会被重置。而这些临时保持的状态,根本没有必要进入中心化管理的状态管理器中,一旦进入中心化状态管理器,那么就遇到内存持久不能释放,还要解决数据重置等问题。但尴尬的场景又在于,如果不进中心化状态管理器,那映射思想又无法完全实现,一个状态一定对应一个界面的理想模式无法复现。这个问题,只要是共享数据,都会碰到,不一定是共享状态,共享一个函数,共享一个模块,共享一个类的实例,都会遇到,所以,这是共享问题带来的普遍性问题。
还有一个大问题,集中管理状态的代价是状态的domain问题。一份完整的状态确实好处多多,但是带来的问题是,原本和组件无关的状态变化,也会因为状态整体的变化被通知重新执行virtual dom的diff操作。不过这是有办法解决的,无论是通过状态管理器自身的优化也好,还是通过组件的优化也好,都可以做到根据需要的状态变化来决定自身是否要做这个diff。可是大状态始终是个隐患,不仅面临内存问题,也面临数据重复、难相互依赖等问题。
直到react hooks出现,这个局面又被打破。hooks虽然表面上是让functional组件也可以在不同的生命周期环节上执行某些任务,但是本质上是重新定义组件在什么情况下重新diff。hooks函数的重点不在第一个参数,而在第二个参数(依赖)。当依赖发生变化时,需要执行对应的变化。变化源自状态的变化。hooks依赖状态,但是实际上定义的是动作及其触发的条件。
# 状态不是状态,而是动作。
从更小粒度去解释,视图层的每一个变化,是完成什么动作。这就是hooks带来的变化。这个粒度小到什么程度呢?atom。Recoil是facebook发布的一个状态管理工具,基于hooks的技术,实现状态共享。和集中管理状态不同,recoil是小到原子级别的状态管理。通过atom定义一个原子状态,通过selector定义一个依赖原子状态的复合状态(相当于计算属性),再依托hooks,实现状态共享。由atom定义的原子状态,它的状态到底是什么并不重要,我们不需要取出来看看,我们要做的,是在hooks加持下,把握住状态变化的所带来的影响,也就是每一个动作。
听上去就像在胡扯,事情会变得越来越复杂。设计,核心是简单。这里的简单,不单单是使用起来很简单,而且理解起来也要很简单。对于一个工具而言,我们要止于至简。我们追求简单,但防止过犹不及。在设计工具时,有的时候,我们可以设计出超强超灵活的能力,但是,超出简单部分的功能,往往使得使用成本和理解成本极速上升。状态管理器的本质,是管理状态,是共享状态。过度设计,过度技术化,都是过犹不及。当recoil发布的时候,大家开始讨论actor model,这是过犹不及。我们做开发设计,并非遵循某个模型进行设计,而是遵循使用者的使用习惯进行设计。当然,我不是说要迁就使用者,而是说让使用者付出最低的成本得到最高的回报,简单原则是达到这一目标的终极武器。为了简单,我们有的时候不得不放弃一些原本可以让工具更强大的能力,但是不要着急,这给我们开发工具提出了另外一个要求,就是扩展性。简单是对使用者说的,而扩展性则是对开发者说的。通过扩展性,简单工具可以变成功能强大的功能,扩展性设计是考验能力的,并非每个开发者都能做到,但是,这是基本面。
挑选优质特性
应用没有“有意识地管理状态”并非不行,以最早的jquery.data方式管理一个状态也未尝不可。但如果需要有意识的进行状态管理,那么,我们不得不需要一个状态管理器。虽然我们可以挑选市面上已有的状态管理器,但我们可能并不需要。我认为redux之所以经久不衰,核心的核心就在于简单。然而,并不是简单我们就一定要用它,如果它的简单正好符合我们的实践场景,那么它是不二之选,但是它的简单在应对我们的场景的时候略有不足,由于木桶原理,它将永远无法满足我们的要求。所以,手撸状态管理器在所难免。
当然,我们手撸,并不代表我们要全撸,例如,我们可以基于已有的redux,利用它的扩展性,撸出自己的状态管理器。然而核心要点还是在于,如何提供低成本的使用者开发体验。我们基于redux撸出来的,我们可以另外取一个名字,将我们的用法和接口暴露给使用者,我们全然不提redux,使用者但凡用的舒服,没有吐槽,就代表这是成功的,此时我们再提redux,会让我们的成果充满乐趣。而如果一开始就大书特书我们是基于redux的,想加持光环,那么得到的结果必然是,如若不是真的好用到爆炸,断然收不到好评。
既然要开始撸状态管理器,我们就要设计这个状态管理器的核心特质,缺少这些特质会是我们自己都无法忍受的。
简洁的状态定义,拒绝reducer 状态domain,拒绝庞大状态树的细小变动都惊动整个virtual dom重新计算 回溯能力,可撤销变化 重放能力,整个应用可以根据时间线完整播放 局部状态可销毁,以释放内存 局部的共享,基于某一系列流程的临时状态,当这一系列流程结束时,共享状态可销毁 同时支持hooks和class components 简洁的状态更新方式,深层节点更新不需要写非常复杂的解构 优雅的异步支持其中,简洁的状态更新方式有一个库可以推荐:immer。这个库只有一个接口,它的使用方式如下:

大道至简!大道至简!大道至简!immer的作者简直就是天才。使用immer遵循了immutable的社区范式,同时又可以采用mutable的操作方式,虽然在实战中确实还有些坑,然而,对比原本写一大堆解构符号的做法,这个接口简直是上帝的馈赠。
还有一个点需要单独指出,重放功能实际上并不是强制的,因为对于大多数应用而言,要实现完全的重放,其实是不大可能的,最严重的原因有两点:1)我们无法穿透所有组件,在大部分组件中,我们不可避免的会用到内部状态,而这些内部状态的变化我们无法收集到,因此,也就无法重放由于组件的内部状态变化带来的界面变化,一旦无法重放界面变化,就会出现问题,因为DOM的变化具有副作用,下一个DOM树的基础是上一个DOM树,如果某些变化没有发生,后续变化所依赖的DOM节点可能根本就不存在,应用会报错;2)在状态中,我们不可避免的使用某些实例对象,基于class的实例对象有内存依赖,我们无法将它们保存到服务器端,再从服务器端拉出来进行回放。由于这两个原因,实际上要完全回放一个应用,是很难的。
有没有其他方向?
有的。我们谈状态管理,本质上无法摆脱应用层面的架构思维,而且这里仅仅是指围绕数据流的前端应用(Management System、Data Application),我们几乎很少在游戏这种视觉系统中大谈前端状态管理。既然是Management System,那么我不禁要问,状态管理的目的,是技术的,还是应用的?很显然,状态管理的目的,是为了让应用系统良好运作,保障系统工作稳定准确。而我们要面对的实际情况是什么呢?并非如何在组件之间共享状态。我们的实际情况是,我们需要在不同子模块之间协调,甚至,我们需要在不同的客户端之间协调。这里面的核心点实际上是“业务逻辑”。如果我们同时拥有手机端和PC端应用,虽然它们在视图层面完全不同,然而在business层面,却是一定一致的,否则系统就不可靠了。如何保障业务层面的一致性呢?
对于服务端应用而言,特别是今天这个时代,分布式系统已经是基础范式了,多个节点如何保障同一个用户的业务操作是一致的,实际上,它们还是要共享一个状态,这个状态可能存在redis中,可能通过Kafka进行同步。业务逻辑的推进,依赖这些状态。看看后端是怎么处理的?在模型中专注于整理出每一个业务原子操作,并在接收到特定事件(或请求)时,按照业务顺序,组装完整的业务逻辑出来。而现在前端是怎么做的?以react为例,几乎全部的react应用,都是将业务逻辑写在组件中,因为业务操作必须依赖用户的操作,而用户的操作必须在视图层中予以反馈。所以在react组件中写业务逻辑非常正常,这回到了angularjs的老路子上,特别是强调functional+hooks的写法之后,我很容易想象到未来的react组件和angularjs的controller函数差不多,写出上千行代码也不是不可能,到时候没人敢动这个组件。
而在这一点上,我恰恰发现vue比react好很多。vue的结构是<template><script><style>,这样的结构看上去符合早期的编程习惯,模板样式加脚本嘛!然而,如果再去琢磨vue的script部分,我发现实际上vue所export出去的对象,本质上是一个类似模型的定义(类似配置对象)。
{
data,
computed,
methods,
watch,
}
一个模型,总是围绕自己目标所需要的数据进行处理。如果写过php应用,大部分php框架都会有模型层,而在编写模型时,强调的,都是只进行数据的读写和计算,而不处理任何视图的东西,处理视图的东西,需要在控制器中读取模型上的数据,自己进行组装。所以,模型,是对单一目标数据的总体概括,具有业务逻辑的抽象性,无法单独完成整个业务流程,但是却规定了业务逻辑的核心部分,等待开发者使用这些部分,组装出完整的业务流程。
不过,vue的组件定义不仅仅包含这些东西,同时还有生命周期函数,子组件引用,props,视图事件回调函数等等东西,而这些东西的整体,又是为视图编程服务的,因此,最终它和模型也只是插肩而过。状态管理的下一个方向,我恰恰认为是去弥补这个领域。前端架构至始至终,都没有在模型层抽象出犹如后端一致的模型管理,而发展至今,也应该是时候去往这个坑填一填了。所以,我在写完react-tyshemo之后,有一种自豪感。我感觉自己好像触摸到一点点这个问题的边缘了。这个库,可以做到定义状态就定义状态,在定义函数中,把状态的所有演变都定义完整(也就是和上述vue组件script中的部分子集一致),然后通过connect注入给组件使用,对于组件而言,它就像只能从模型中读取属性和方法一样,在遇到对应的交互事件之后,调用模型上的方法去驱动模型中的状态变化,然后返回来又更新自己。这样就做到了数据模型的定义和视图层(react组件)的分离,在手机端、PC端之间共用同一个模型成为可能。
在react生态里面,炫技的不在少数。但要解决问题,而且要简单地解决问题。将状态管理升级到前端模型构建之后,模型逻辑和视图逻辑就可以完全分离。而由于我们大部分情况下,会在模型中写业务逻辑,在视图中写交互逻辑,所以只需要将它们组装起来。但是,有趣的地方在于,可以拆分开来。而且,这也带来了另一个好处,由于业务逻辑的部分被独立出来,那么在不同端,就可以被复用,手机端、PC端、其他端,可以基于同一个模型,但视图却可以不同,视图因为只负责交互逻辑,所以反而更抽象,变量命名都可以抛开业务单词使用更抽象的词汇来命名。一旦业务逻辑的东西通过模型层面,和react视图编程拆分开,那么,真的就可以做到,react组件负责纯UI,而模型负责纯业务逻辑,中间在通过某种控制器将两者粘连在一起,会是另一翻编程的景象。
最后语
本文主要是想表达,在状态管理这件事上,我们尝试一切,试图找到某种通用的优雅的解决方案,但是,在所有方案中,我们都不得不进行一些妥协。如果我们能够从历史的角度去观察,往往能够发现,世界上没有完美的事物,有一种说法“历史都是妥协出来的”,我们可以换一个好听的词,叫“博弈”,但是无论如何,我们都在追求着,每个人的追求不同,代码风格的优雅,代码量少,代码性能极致,代码明显没有bug……这些追求,驱动着我们不断探索和思考。

文章来源:
Author:frustigor
link:https://cdc.tencent.com/2020/05/22/frontend-state-management-research/