什么是DB的三星索引
上一篇《Sql优化器究竟帮你做了哪些工作?》讲解了,sql优化器所做的工作,有不少同学询问,为何没有看到如何设计索引,这一篇主要来讲解下索引设计中需要遵循的规范。
这是数据库设计第三篇:
《Sql优化器究竟帮你做了哪些工作?》
《DB——数据的读取和存储方式》
如果你从网上或者教程中,查询索引设计相关规范,常常会看到一些不知所云的规则和注意事项,这些规则看似很有道理,但等你应用时,会发现仍然让你一头雾水,不知如何下手,就像我们提到的知识的边界一样,这些干涩的知识点,对我们的索引设计并没有任何帮助,只能令DB新手望而却步。
本篇尝试从《Relational Database index design and the optimizers》书中提到的三星索引,提炼出索引设计的准则和原理,期待能够对索引设计准则起到一个锚定作用,期待大家一起探讨学习。
从本文,你可以学习到:
什么是三星索引
三星索引的原理是什么
如何设计最佳索引
table
CREATE TABLE `test` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_name` varchar(100) DEFAULT NULL, `sex` int(11) DEFAULT NULL, `age` int(11) DEFAULT NULL, `c_date` datetime DEFAULT NULL, PRIMARY KEY (`id`), # 索引 KEY `id_name_sex` (`id`,`user_name`,`sex`), KEY `name_sex_age` (`user_name`,`sex`,`age`) ) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8;
一、失败的索引应用
我们假设 talbe test 里面有10000行数据,其中 user_name 有100种不同的值,其FF=1%,我们查看以下两个sql:
sql1: select user_name,sex,c_date from test where user_name ='test0' order by sex sql2: select user_name,sex,c_date from test
以上我们可以预测到:
sql1 要比sql2 的查询速度快,因为sql用到了索引
name_sex_age,而sql2 是全表扫描。
那么真实情况是这样么?
我们加上查询打印时间,查看下:
select user_name,sex,c_date from test where user_name ='test0' order by sex; 101 rows in set (0.02 sec) select user_name,sex,c_date from test; 10013 rows in set (0.01 sec)
以上我们可以看到,全表扫描(sql2)的耗时要低于用索引(sql1)的耗时,这是为何?
sql1 中,虽然用到了索引,但用的是辅助索引name_sex_age, 再加上 select的时候是全行查询,所以从索引片检索出数据之后,还要去聚簇索引中查询一次,这就产生了大量的随机IO,从上一篇《》中,我们知道随机IO会占用大量的查询时间的。
我们不考虑数据库缓存以及磁盘缓存
sql1 查询耗时=10ms(第一次查索引IO)+0.01ms100(索引行,顺序读取)+10010ms(主表随机读) =1010 ms
sql2 查询耗时=10ms(第一次查索引IO)+0.01ms*10000(索引行,顺序读取)=110 ms
那么我该如何设计我们的索引,以及查询?
二、三星索引
对于一个查询而言,一个三星索引,可能是其最好的索引。
如果查询使用三星索引,一次查询通常只需要进行一次磁盘随机读以及一次窄索引片的扫描,因此其相应时间通常比使用一个普通索引的响应时间少几个数量级。
那么索引的星级是如何定义?
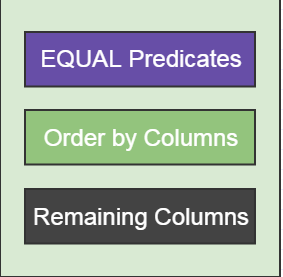
第一颗星:与查询相关的索引行是相邻的,也就是where后面的等值谓词,可以匹配索引列顺序
第二颗星:索引行的顺序与查询语句需求一致,也就是order by 中的排序和索引顺序是否一致
第三颗星:索引行包含查询语句中所有的列
三颗星的意义
第一颗星,也是我们上篇文章所提的匹配列,where后面的谓词和索引列匹配的越多,索引片越窄,最终扫描的数据行也是越小
第二颗星,是避免排序,如果结果集采用现有顺序读取,那么就会避免一次排序,避免提前物化结果集
第三颗星,避免每一个索引行查询,都需要去聚簇索引进行一次随机IO查询
上述中第三颗星也是我们常说的宽索引,它可以保证查询只需访问索引而无需访问表。
比如我们上述的查询:
select user_name,sex,c_date from test where user_name ='test0' order by sex; 最终需要的三星索引是: (user_name,sex ,c_date)
三、最佳索引——多种方案
三星索引是一种理想的索引设计方式,真实情况中往往很难达到,它是一个标尺或者是引路人的方式,要求我们设计索引时必须要注意的要素。
现实情况往往很难达到三星索引,我们分情况来进行说明。通常情况下,第三颗星(索引行包含查询语句中所有的列)是最容易达成的,第二、三星往往不能够一起达成。
select user_name,sex,age from test where user_name like 'test%' and sex =1 ORDER BY age
索引1,(满足第一、三颗星,无排序)
(
user_name,sex,age)
三星索引对齐:
第三颗星,满足,select查询的列都在索引列中
第一颗星,满足,user_name 可以匹配到一个索引列列 user_name和一个过滤列sex,他们是相邻的
第二颗星,不满足,user_name 采用了范围匹配,sex 是过滤列,此时age 列并不是有序的,不满足 order by age要求
上述我们看到,此时索引(user_name,sex,age)并不能满足三星索引中的第二颗星(排序),想要满足必须得让 age 列在 user_name 列前面,索引我们才去方案2
索引2(满足第二、三颗星,无窄索引片)
(
sex,age,user_name)
三星索引对齐:
第一颗星,不满足,只可以匹配到sex 索引列,sex索引列是一个宽索引片
第二颗星,满足,等值sex 的情况下,age是有序的
第三颗星,满足,select查询的列都在索引列中
对于索引(sex,age,user_name)我们可以看到,此时无法满足第一颗星,窄索引片的需求。
以上2个索引,都是无法同时满足三星索引设计中的三个需求的,我们只能尽力满足2个。而在多数情况下,能够满足2颗星,已经能缩小很大的查询范围了,具体最终要保留那一颗星(排序星 or 窄索引片星),这个就需要看查询者自己的着重点了,无法给出标准答案。
三、宽索引
在三星索引中,第三颗星要求(索引行包含查询语句中所有的列),也就是常说的宽索引。
这颗星很好达到,又很难把控。或者说,为了达到这颗星,是否应该把所有的列都设计到索引列里面?
如果每个索引中包含表的所有列,首先能带来的优势是,匹配到的sql查询更多,查询到的数据不用在进行聚簇索引查询,节省了随机IO。
但劣势也很明显,长列索引会造成频繁的page split 和 page merge ,每个page能够存入的索引数据更少,而且会有更多的 page split,这对插入和查询来说,效率都会降低不少。
那我们应该怎么做,我们要回顾索引设计的本心,设计索引是为了方便查询的,而不是只为设计索引,脱离了查询的索引设计,并不高效。
宽索引要求我们尽量包含多的列在索引中,并不是所有,所以除了针对where 后的常用谓词,我们要设计索引以外,我们还得为常用select 后面的谓词,加入到索引,以加快查询速度。
文章来源:
Author:wier
link:https://my.oschina.net/u/1859679/blog/1589575