Java应用异常状态监测
老板最近分派了一个任务,说线上客户在部署应用的时候发生了系统级别的OOM,触发了OOM Killer杀掉了应用,让我们解决这个问题。
对于这个任务,我从如下几点开始调研、分析与解决。
1、什么是系统级别的OOM(Out-Of-Memory)?
当创建进程时,进程都会建立起自己的虚拟地址空间(对于32位系统来说为4g)。这些虚拟地址空间并不等同于物理内存,只有进程访问这些地址空间时,操作系统才会为其分配物理内存并建立映射。关于虚拟内存和物理内存有很多资料,这里不再赘述,这篇文章写的通俗易懂,可以看下。
通过虚拟内存技术,操作系统可以允许多个进程同时运行,即便它们的虚拟内存加起来远超过系统的物理内存(和swap空间)。如果这些进程不断访问其虚拟地址,操作系统不得不为它们分配物理内存,当到达一个临界点时,操作系统耗尽了所有的物理内存和swap空间,此时OOM就发生了。
2、系统发生了OOM会怎么样?
当发生了OOM,操作系统有两个选择:1)重启系统;2)根据策略杀死特定的进程并且释放其内存空间。这两种策略当然是第二种影响面较小,由于我们线上系统也是采取杀死特定进程的策略,因此这里只展开第二种。
第二种行为也称之为OOM Killer。那系统会杀死什么样的进程释放其内存呢?这篇文档的“Selecting a Process”部分大概描述了Linux内核的操作系统选取算法:首先,根据badness_for_task = total_vm_for_task / (sqrt(cpu_time_in_seconds) * sqrt(sqrt(cpu_time_in_minutes)))来算起始值,total_vm_for_task为进程占用的实际内存,cpu_time_in_seconds为运行时间,这个公式会选取占用内存多且运行时间短的进程;
如果进程是root进程或者拥有超级用户权限,那么上述得分会除以4;
如果进程能够直接访问硬件(也就是硬件驱动),那么将得分再除以4。
但文档中描述并不完整,这个是Linux内核OOM_Killer的相关代码,然后这篇文章对代码进行了分析,除了上述因素之外还包含子进程内存、nice值、omkill_adj等因素。
操作系统会对每个进程进行计算得分,并记录在/proc/[pid]/oom_score文件中;当发生系统OOM时,操作系统会选取评分最高的进程进行杀死。
3、如何实现系统OOM告警?
OOM告警有两种方式,如下:
提前OOM告警:在系统即将发生OOM时,发出告警信息。
事中/事后告警:在系统完成OOM Killer杀死进程后,发出告警信息。
提前OOM告警是最好的方式,但实际上如果想达到不误报、不漏报,实现难度极大。我们线上应用为Java应用,考虑这么个场景:客户应用不断申请内存,当系统物理内存占用率达到90%的时候,系统及应用下一步行为会是什么样?个人认为有三种可能性:1)Java应用停止申请内存,并且进行了垃圾回收释放内存,这样系统将会恢复正常;2)应用继续申请内存导致应用内存超过了堆大小,但此时系统仍然有部分物理内存,这样会发生Java应用的OOM;3)应用继续申请内存导致系统耗尽物理内存,但此时没有超过堆内存的最大值,这样会发生操作系统的OOM。对于这个场景来说,我们想准确预判出系统及应用的下一步行为难度极大。
另一方面,我们线上其实已经有基于机器内存使用率的报警,这个报警其实已经包含了三种可能性:1)应用本身有问题但不会导致堆溢出或者系统OOM;2)应用可能会导致堆溢出;3)应用可能会导致系统OOM。无论实际情况为哪一种,这个报警都是有意义的。
事中/事后告警也是一种可取的方式,原因在于:1)这种方式能够实现不误报、不漏报;2)对于即将发生OOM的应用来说,事中报警与事前报警时间相差其实并不大。另外,到目前为止客诉的情况都是抱怨其应用死了没有任何通知,排查起来既浪费了客户时间,也浪费了研发排查问题的时间。
综合考虑,如果能够实现Java应用的异常状态检测并提供事中/事后报警与现场分析,也是很有意义的!
4、Java应用的异常状态为哪些?
这里定义的Java应用异常状态有:
Java应用被用户杀死(Kill、Kill -9);
Java应用发生堆溢出;
Java应用被系统OOM(Kill -9)。
5、如何检测出上述Java应用异常状态?
首先,Java应用发生堆溢出可以通过-XX:+HeapDumpOnOutOfMemoryError参数来生成dump信息,我们可以通过轮询方式即可发现是否发生堆溢出(当然基于事件通知方式更好,待调研)。
因此,现在问题在于我们怎么发现一个Java应用被用户杀死或者被系统OOM Kill掉?
5.1 ShutdownHook/sun.misc.Signal
老司机可能很快就想到,通过注册shutdownHook就可以检测到系统信号了呀!注册shutdownHook的确能检测到SIGTERM信号(也就是通常不带参数的Kill命令,如Kill pid),但不能检测到SIGKILL信号(Kill -9)。另外,调研发现也可以通过sun.misc.Signal.handle方法来检测系统信号,但遗憾的是还是不能检测到SIGKILL信号。
5.2 strace
这个工具非常强大,它能够拦截所有的系统调用(包括SIGKILL),并且具有系统已经内置、使用方便、输出信息可读性好等优点。下图是我的一个实验(进程24063是一个触发系统OOM的Java进程):
 1
1
但这个工具的缺点是,被跟踪的应用的性能影响非常大。应用原来进行系统调用(比如open、read、write、close)时会发生一次上下文切换(从用户态到内核态),使用了strace之后会变成多次上下文调用,如下图所示: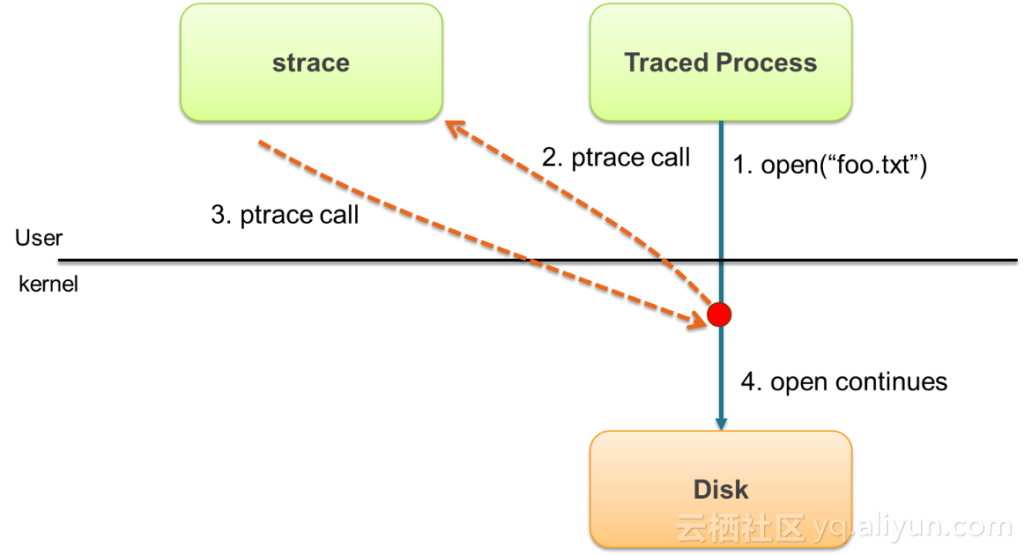 2
2
(更多信息可以参考这篇文章)
但无论如何,我们已经找到一种可行的解决方案,虽然性能影响很大,但可以作为debug方案开放给客户。
5.3 ftrace + 系统日志
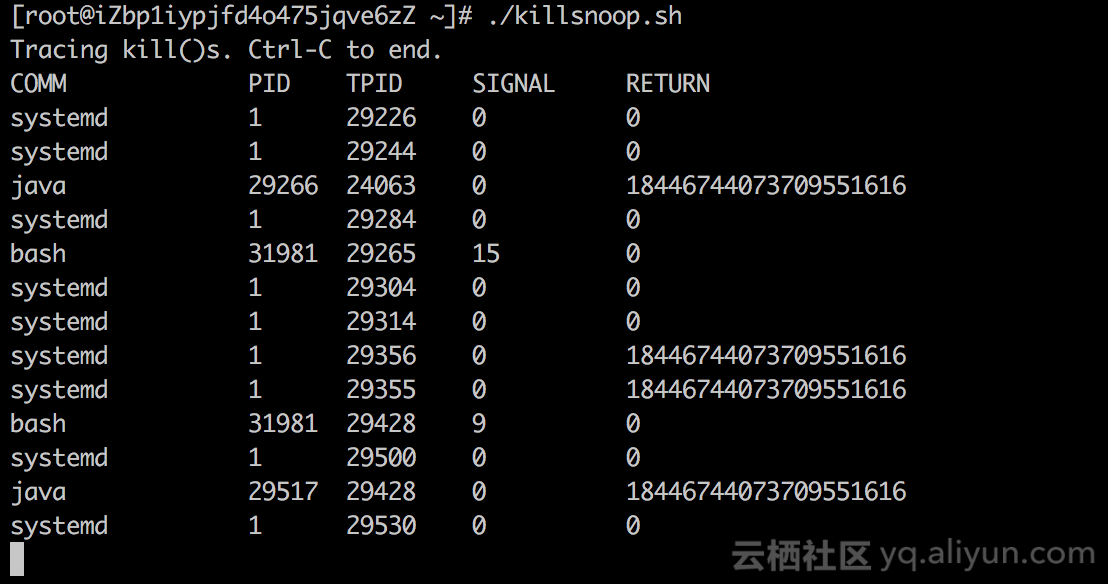
ftrace是Linux系统已经内置的工具(debugfs挂载情况见附录),它的作用是帮助开发人员了解 Linux 内核的运行时行为,以便进行故障调试或性能分析。重要的是,它对应用本身的性能影响极小,而且我们可以只检测Kill事件,这样对客户应用几乎零影响(性能分析见第6节)。在我们的场景下,它也支持内核事件(包括进程SIGKILL信号)监听。ftrace使用起来非常方便,可以参考这篇文档,或者直接使用这个GITHUB脚本即可。下面是运行该GITHUB脚本的一个截图:
 3
3
在上图中,SIGNAL为15的是我执行Kill 29265命令,SIGNAL为9的是我执行Kill -9 29428命令。但这个工具的问题在于,当Java进程触发系统级别的OOM Killer时,并没有检测到相应的信号(待进一步调研)。
另外,当系统触发OOM Killer时,会在系统日志(Centos的为/var/log/messages)中记录下特定信息,如下所示:
 4
4
5.4 auditd + 系统日志
(系统日志用来发现OOM信息,不再赘述,下文主要介绍auditd)
同事建议可以尝试下auditd,因此这里调研auditd,发现它能满足需求,而且测试性能影响比ftrace更小(性能分析见第6节)。auditd是Linux Auditing System(Linux审计系统)的一部分,它负责接收内核中发生的事件(系统调用、文件访问),并将这些事件写入日志供用户分析。
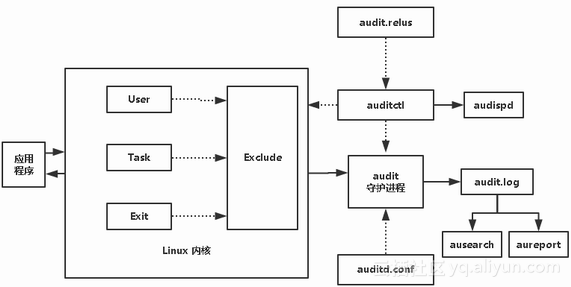
下图是Linux审计系统的框架:
 5
5
其中:
左边是我们的应用程序;
中间为Linux内核,内核中包含了审计模块,可以记录三类事件:1)User:记录用户产生的事件;2)Task:记录任务类型(如fork子进程)事件;3)Exit:在系统调用结束时记录该事件。同时,可以结合Exclude规则来过滤事件,最终将这些事件发送到用户空间的auditd守护进程;
右边是在用户空间的应用程序,其中auditd是核心的守护进程,主要接收内核中产生的事件,并记录到audit.log中,然后我们可以通过ausearch或者aureport来查看这些日志;auditd在启动时会读取auditd.conf文件来配置守护进程的各种行为(如日志文件存放位置),并读取audit.rules中的事件规则来控制内核中的事件监听及过滤行为;另外,我们也可以通过auditctl来控制内核事件监听和过滤规则。
关于更多信息可以自行搜索或者看下这篇文章。
内核已经内置审计模块,而auditd守护进程也默认在centos(>=6.8)中启动,下面我们来测试下该工具。首先,我们执行如下命令:
auditctl -a always,exit -F arch=b64 -S kill -k test_kill
这条命令作用是,在kill系统调用返回时记录事件,并且绑定test_kill标记(以便后面进行日志筛选)。然后,我们可以随便执行一个脚本并kill掉,可以在/var/log/audit/audit.log中看到如下输出:
 6
6
第一条SYSCALL日志记录发送SIGKILL信号的进程信息,第二条OBJ_PID日志记录接收SIGKILL信号的进程信息。
5.5 Shell + dmesg
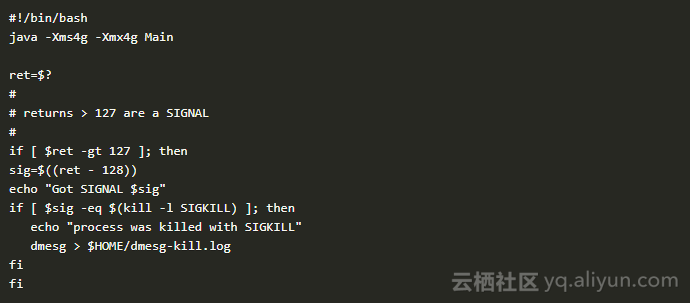
如果我们能够控制Java应用的启动脚本,那么此方式是影响最小的方案。先看下面这个shell脚本:
 7
7
这个脚本做了这几个事情:
使用Java -Xms4g -Xmx4g Main来启动一个Java应用;
Java应用退出后通过$?获取程序退出状态码;
如果退出码大于128,则为应用收到SIGNAL退出;如果为SIGKILL,则通过dmesg收集kernal ring buffer中的信息。
如果应用由于被OOM Killer杀死而退出,则dmesg-kill.log中会有如下信息:
 8
8
此方案优点在于影响面最小,但进程杀死信息量相比auditd少,只知道收到何种SIGNAL信号;而auditd能够知道SIGNAL信号来源于哪个进程、用户、组。
6、性能测试
6.1 测试环境
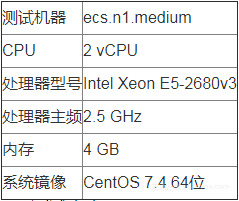 1
1
6.2 测试脚本
6.2.1 测试一:系统调用性能影响
测试方法
从/dev/zero中读取500个字节数据并写入到/dev/null中,循环执行1亿次(也就是100M):
dd if=/dev/zero of=/dev/null bs=500 count=100M
该脚本会产生大约2亿次系统调用(read 1亿次,write 1亿次)。
测试结果
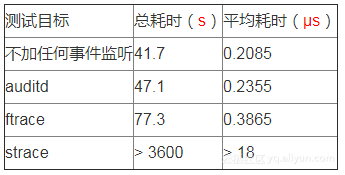 2
2
6.2.2 测试二:JAVA应用性能影响
测试方法:
构造consumer和provider应用,consumer向provider发起HSF调用,provider返回预定义数据,循环调用1百万次,观察consumer耗时。
测试结果:
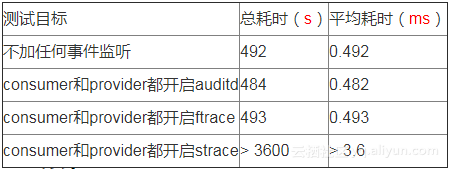 4
4
7、总结
综上,我们可以通过如下手段来解决客户的应用OOM问题:
使用机器的基于内存使用率报警来事前通知客户;
JVM启动参数可以添加-XX:+HeapDumpOnOutOfMemoryError等参数来协助收集JVM内存溢出信息;
通过系统日志(/var/log/messages)或者dmesg来收集系统OOM Killer信息;
使用启动shell脚本(见5.5节)或auditd(见5.4节) ftrace 来获取应用被Kill掉的信息(可能被客户自身Kill掉)。
【可选】开放strace工具来帮助客户debug问题。8、其他工具
8.1 trap
trap命令用于指定在接收到信号后将要采取的动作,通常在脚本程序被中断时完成清理工作。当shell接收到sigspec指定的信号时,arg参数(命令)将会被读取,并被执行。下面我试图拦截当前脚本的SIGTERM和SIGKILL信号:
 6
6
测试发现,trap命令能够检测到当前进程的SIGTERM信号,但是无法检测SIGKILL信号。这个命令相当于Java应用中的shutdownHook或者Signal。
9、附录
9.1 ftrace系统debugfs挂载情况
(注:以下统计阿里云上主要的操作系统)
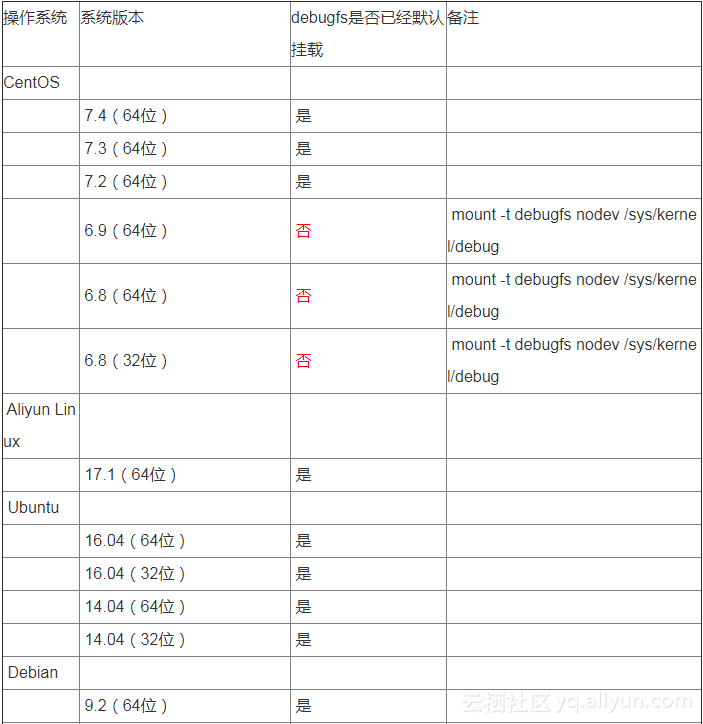 7
7 8
8
文章来源:
Author:阿里中间件
link:http://jm.taobao.org/2018/06/26/Java应用异常状态监测-1/